

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
自定义 Stable Diffusion 以释放您的创造力
6 个月前

照片由
您好!看起来您可能没有提供完整的句子或上下文。如果您需要翻译某个词或句子,请提供更多信息,我会尽力帮助您。如果您需要翻译短语 "on",它在中文中通常翻译为“在……上”或“开启”。如果您有其他问题或需要进一步的帮助,请随时告诉我。
概述
你曾经尝试过生成一个在其他地方都找不到的独特图片吗? 我们很幸运生活在人工智能时代。人工智能发展迅速,现在变得更加易于获取。大多数开源模型都经过了良好的训练,拥有来自广泛类别的相当数量的数据,因此我们可以生成许多不同类别的图像。 如果模型从未学习过我们想要生成的具体主题,会发生什么呢?例如,我想要生成我今天早上刚做的蛋糕的图像。尽管模型可以生成无数种蛋糕图像,但模型不知道如何生成我刚刚制作的蛋糕的图像。
在这种情况下,模型生成的图像将基于它在训练过程中学到的模式和特征。它可能会生成一个看起来像蛋糕的图像,但可能与您实际制作的蛋糕在细节上有所不同。这是因为模型没有关于您特定蛋糕的任何信息,它只能依靠其训练数据中的知识来生成图像。
要解决这个问题,您可以采取以下几种方法:
-
提供参考图像:如果可能的话,提供一些与您想要生成的蛋糕类似的参考图像。这可以帮助模型更好地理解您想要的蛋糕的外观。
-
使用条件生成模型:某些生成模型,如条件生成对抗网络(Conditional GANs),允许您提供额外的条件或标签来指导图像生成过程。例如,您可以指定蛋糕的特定风格、颜色或装饰。
-
微调模型:如果您有一组特定的蛋糕图像,您可以使用这些图像来微调现有的生成模型,使其更好地适应您的需求。
-
使用定制数据集:创建一个包含您想要生成的蛋糕类型的数据 尽管从头开始训练对于个人来说几乎是不可能的,但借助不断发展的模型微调技术,将新主题纳入模型可以变得轻而易举。自2022年以来,Stable Diffusion作为最新的趋势生成模型,为图像生成开启了一个全新的时代。 在这篇文章中,我想分享如何使用现代技术LoRA对Stable Diffusion模型进行微调的逐步指南。整个练习都在Kaggle笔记本上进行,这样每个人都可以在不用担心拥有合适设备的情况下完成这个练习。
-
理解Stable Diffusion模型:首先,了解Stable Diffusion模型的基本原理和它在图像生成中的应用。
-
获取LoRA技术:LoRA是一种微调深度学习模型的技术,它通过在模型的现有层中引入额外的可训练参数来实现。
-
设置Kaggle环境:登录Kaggle并设置你的Kaggle笔记本环境,确保你有足够的计算资源来运行模型。
-
下载Stable Diffusion模型:从官方源或可信的第三方源下载预训练的Stable Diffusion模型。
-
准备数据集:收集并准备用于微调的数据集,这可能包括特定的图像或文本提示,以指导模型生成。
-
应用LoRA技术:按照LoRA的指导原则,在你的Stable Diffusion模型中引入新的可训练参数。
-
训练模型:使用你的数据集和LoRA调整的模型进行训练。监控训练过程, 在我们深入实现之前,让我们快速了解一下稳定扩散(Stable Diffusion)的概念以及微调技术LoRA。如果你已经熟悉了背后的知识,可以直接跳到实现部分。
稳定扩散是一种生成模型,它能够根据给定的文本描述生成图像。它通过学习大量图像和文本对的数据集来实现这一点。稳定扩散模型通常使用一种称为扩散过程的方法来生成图像,这种方法模拟了图像从噪声状态逐渐演变到清晰图像的过程。
LoRA(Low-Rank Adaptation)是一种微调技术,它通过在预训练模型的权重矩阵中引入低秩结构来实现模型的快速适应。这种方法可以显著减少模型参数的数量,同时保持模型性能。LoRA通常用于在特定任务上微调大型预训练模型,以提高模型在该任务上的表现。
如果你对这些概念已经有所了解,可以直接跳到实现部分,我们将详细介绍如何使用LoRA技术对稳定扩散模型进行微调。 稳定扩散

图 1. 稳定扩散中的反向扩散。来源:作者提供的图片。 Stable Diffusion 是一种生成式人工智能模型,能够根据文本和图像生成逼真的图片。扩散模型在潜在空间而非图像空间上施展魔法,这使得图像生成对公众更加容易,因为所需的计算能力较低。人们甚至可以在CPU机器上,利用喝咖啡的休息时间生成一个不存在的图像。 有许多面向公众和开发者的在线稳定扩散平台,例如HuggingFace¹和Stable Diffusion Online²。我们可以在没有机器学习知识的情况下生成图像。
- HuggingFace: HuggingFace
- Stable Diffusion Online: Stable Diffusion Online LoRA(低秩适应)
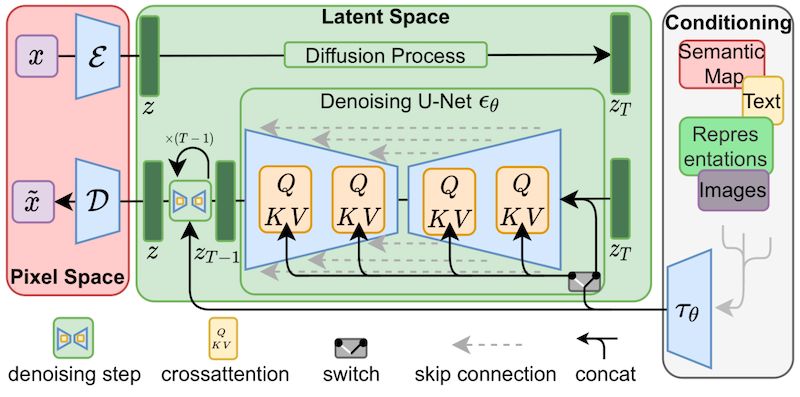
图 2. 稳定扩散网络。来源:
LoRA 是一种微调方法,它在稳定扩散网络的交叉注意力层中添加了额外的权重。交叉注意力层在图 2 中用黄色块表示。交叉注意力层融合了图像 ZT 和文本 τθ 的中间信息。向交叉注意力层添加权重扩展了文本提示和图像之间的相关性。这就是 LoRA 如何向稳定扩散模型引入新知识的方式。 修正后的权重被分解成更小的(低秩)矩阵。这些较小的矩阵包含的参数更少,并且分别存储。这就是为什么LoRA权重文件大小可控,但必须与底层的稳定扩散模型一起使用的原因。 LoRA的权重大小通常在2到200MB之间。这是共享和管理模型的一个优势。与其以几个GB的完整模型进行共享,共享更小尺寸的LoRA权重更加高效。 环境
练习是在Kaggle笔记本中进行的,环境设置如下: * NVIDIA Tesla P100(RAM=16G) * diffusers-0.30.0.dev0 * PyTorch 2.1.2 * Python 3.10 Kaggle 笔记本已经安装了 Python 和 PyTorch。我们需要安装的唯一库是来自 HuggingFace 的 Diffusers。 我们可以使用以下命令从源代码安装Diffusers。从源代码安装可以确保获得库的最新版本。路径/kaggle/working是Kaggle运行时的默认工作空间。您可以调整路径以适应您的开发环境。 %cd /kaggle/working/ !pip install accelerate !git clone https://github.com/huggingface/diffusers %cd /kaggle/working/diffusers !pip install /kaggle/working/diffusers/. -q %cd /kaggle/working/diffusers/examples/text_to_image !pip install -r /kaggle/working/diffusers/examples/text_to_image/requirements.txt -q !pip install --upgrade peft transformers xformers bitsandbytes -q
更多安装指南可以在
您好,您似乎没有提供需要翻译的内容。请提供一段英文文本,我将很乐意为您翻译成中文。 实验
在这次练习中,我想介绍
将小雕像转化为模型。让我们在接下来的章节中逐步进行。 第一步:数据收集

图 3. 训练样本。来源:作者提供的图片。 首先,我们需要收集一些主题的图片。在这个练习中,我们收集了25张蜡笔小新公仔的照片作为我们的训练数据。一些样本可以在图3中找到。以下是我遵循的数据收集建议:
- 确保图像多样性:收集不同角度、不同光照条件下的图片,以确保模型能够泛化到各种情况。
- 图像质量:确保图片清晰,分辨率足够高,以便模型可以识别出细节。
- 背景简单化:尽可能使背景简单,避免杂乱,这有助于模型更准确地识别主题。
- 图像标注:如果可能的话,对图像进行标注,这有助于训练过程中的监督学习。
- 数据平衡:确保各类别(如果有多个类别)的图像数量均衡,以避免模型偏向某一类别。
- 数据增强:考虑使用数据增强技术,如旋转、缩放、裁剪等,以增加数据集的多样性并提高模型的鲁棒性。
遵循这些建议可以帮助你收集高质量的训练数据,从而提高模型的性能和准确性。 1. 标准化图像尺寸:例如,512x512。 2. 高图像质量:照片以1200万像素的分辨率拍摄。 3. 保持主题在图像的中心。 此外,训练集中尽可能多地涵盖多样性也很重要,这样模型就能学习到角色的一般特征,比如眼睛、发型和身材。换句话说,我们希望模型学习的是蜡笔小新公仔的特征,而不是特定穿着风格(例如红色T恤和黄色短裤)和姿势(例如站立)。 我已经在5、15、25的训练大小上进行了实验。尽管每轮之间只有10张图像的差异,但模型的泛化程度显著提高了。 第2步:基线评估
``` from diffusers import AutoPipelineForText2Image
pipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda") prompt = "A crayon shin-chan figurine." image = pipeline(prompt, num_inference_steps=100).images[0] image.save("baseline.png") ```
在开始训练之前,我们想要检查预训练模型是否已经知道我们想要使用上述Python脚本进行微调的特定小雕像。 1. AutoPipelineForText2Image 类用于加载预训练的稳定扩散模型。
您好,您似乎没有提供需要翻译的内容。如果您有任何英文文本需要翻译成中文,请提供文本,我会帮您翻译。 2. 接下来,我们将文本提示设置为“蜡笔小新雕像”。我保持文本提示简洁,以便模型能够直接理解文本信息。 3. 将提示和推理次数传递给 AutoPipelineForText2Image 的实例,并执行生成过程。

图4. 基线评估结果。来源:作者提供的图片。 脚本多次运行,生成的三幅图像如图4所示。结果表明,预训练模型知道它可能是一个人形角色的雕像,但不知道前缀“蜡笔小新”具体指的是哪个角色。生成图像中显示的限制验证了我们微调工作的努力,因为我们的倡议是使用未见过的主体对模型进行微调。 第三步:微调

图5. 蜡笔。来源:图片由
当然,以下是翻译:
from
您好,您似乎没有提供需要翻译的内容。如果您需要翻译服务,请提供一段英文文本,我会帮您翻译成中文。 定义一个新的标识符 除了收集一些图像用于训练外,我们还需要为这个主题选择一个新的名称。每当新名称在文本提示中出现时,修改后的模型就会理解它指的是新的主题,并相应地生成内容。 为什么我们需要一个新名字?难道原始名字“蜡笔小新”不是更具代表性吗?背后的理念是我们需要一个独特的名字,以避免与其他已经训练过的名字混淆。在我们的情况下,“蜡笔”这个词意味着可能与我们用于绘画的蜡笔有潜在联系。如果关联的文本提示包含“蜡笔小新”,生成的图像可能包括与蜡笔相关的内容。 建议使用随机名称作为新的标识符。我选择aawxbc作为这个练习的名称,这个名字几乎不会与任何现有名称重叠。其他人也可以为新主题选择任何其他独特的名称。 训练

图6. 由模型生成的类图像。来源:作者提供的图片。 在Kaggle笔记本中,除了工作空间 /kaggle/working/ 之外,另一个常用的目录是 /kaggle/input/,我们在这里存储工作的输入,例如检查点和训练图像。以下是根据脚本 train_dreambooth_lora.py 的完整训练命令。 ``` !accelerate config default !mkdir /kaggle/working/figurine
!accelerate launch --mixed_precision="fp16" /kaggle/working/diffusers/examples/dreambooth/train_dreambooth_lora.py --mixed_precision="fp16" --pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" --instance_data_dir="/kaggle/input/aawxbc" --instance_prompt="a photo of aawxbc figurine" --class_data_dir="/kaggle/working/figurine" --class_prompt="a photo of figurine" --with_prior_preservation --prior_loss_weight=1.0 --use_8bit_adam --lr_scheduler="constant" --gradient_checkpointing --enable_xformers_memory_efficient_attention --num_train_epochs=50 --output_dir="/kaggle/working/dreambooth-lora" ```
让我们来了解一些关键配置: * mixed_precision [可选]: 选择平台支持的精度。选项包括fp32、fp16和bf16。 * 类别提示 [可选]:存储类别数据的提示和文件夹。在这个实验中,类别名称是 figurine,因为我们希望扩散模型学习一种新的小雕像类型。 * class_data_dir [可选]: 存储模型生成的类别图像的目录。在我们的例子中,模型生成一般的雕像图像,并将它们保存在这个目录下。 * 实例提示[必填]:我们为新主题定义一个文本提示。格式为{新名称} {类名},例如 aawxbc 小雕像,uvhhhl 猫,……等。 * 实例数据目录 [必填]:存储训练样本的目录。在这个练习中,我们将之前提到的25个样本上传到这个目录。 * num_train_epochs [可选]: 训练的轮数。 按照上述步骤,包括数据收集、安装库和完成训练,我们现在可以在由output_dir定义的目录中找到LoRA权重pytorch_lora_weights.safetensors。权重文件的大小为3.2 MB,这是相当容易管理的。 第4步:推理 — 生成新图像
``` from diffusers import AutoPipelineForText2Image
pipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda") pipeline.load_lora_weights("/kaggle/working/dreambooth-lora", weight_name="pytorch_lora_weights.safetensors")
prompt = "A photo of aawxbc figurine." image = pipeline(prompt, num_inference_steps=180).images[0]
image.save("aawxbc.png") ```
成功导出LoRA权重后,我们可以进入最后也是最令人兴奋的部分:生成新图像。请注意,LoRA权重不能独立工作,因此我们需要同时加载原始的稳定扩散和LoRA权重文件。 在Python脚本中,除了我们在基线评估中使用的步骤之外,我们还有一个额外的步骤,即使用.load_lora_weights()函数来加载LoRA模型,通过传入目录和LoRA权重文件的名称。

图7. 使用提示生成的图像:“一个在海滩上的aawxbc小雕像,戴着帽子” 对于文本提示,我们在脚本中包含了标识符aawxbc和类名figurine。图7和图8展示了两组生成的图像及其对应的文本提示。我们可以看到,经过微调后的模型能够生成蜡笔小新的小雕像。

图8. 使用提示:“在森林中,一个aawxbc小雕像,手持一个杯子。”生成的图像。 我们可以进一步通过注释掉加载LoRA权重的行并保持文本提示不变来交叉验证新模型。我们可以看到原始的稳定扩散模型无法正确解释标识符aawxbc,这与基线评估一致,并突显了LoRA模型所贡献的新能力。 摘要
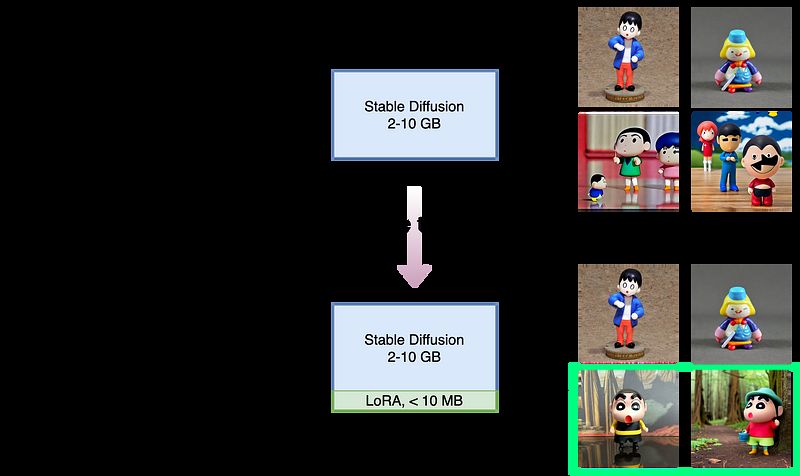
图9. 微调概览。来源:作者提供的图片。 工作概述如图9所示。新模型结合了LoRA权重,并能生成带有新实例名称aawxbc的蜡笔小新公仔图像,如绿色矩形所突出显示的那样。 正如你可能发现的,整个微调过程是直接的。我们所要做的就是收集足够数量的图像,并用一个不存在的标识符来命名新的主题。就这些。所有的艰苦工作都在代码中完成了。 一如既往,感谢您的阅读。我希望这篇文章对您有所帮助。任何反馈都非常欢迎并受到赞赏。 参考
您好,看起来您可能忘记输入需要翻译的内容了。请提供需要翻译的英文文本,我会帮您翻译成中文。如果有特定的格式要求,比如Markdown代码,请一并提供,我会注意保留。
推荐阅读:






赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052