

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
3个AI应用案例(不是聊天机器人)
6 个月前
3个人工智能应用案例(不是聊天机器人)
特征工程、结构化非结构化数据和潜在客户评分
我从(人工智能咨询)客户那里收到的最常见请求是“为我构建一个定制的聊天机器人”。虽然这对于某些问题是一个很好的解决方案,但远不是万能药。在这篇文章中,我分享了三种企业可以利用人工智能在销售领域创造价值的替代方法。这些方法涵盖了生成性人工智能、深度学习和机器学习。

图片来自Canva。
大型语言模型(LLMs)在商业世界中占据了主导地位,现在每个公司都在尝试使用生成性人工智能。虽然像ChatGPT这样的工具显然很强大,但如何让企业可靠地使用这项技术来创造价值仍不明确。
对于我接触的大多数企业来说,“使用人工智能”意味着构建一个聊天机器人、共同助手、人工智能代理或人工智能助手。然而,随着对这些解决方案的初步兴奋逐渐减退,组织逐渐意识到围绕LLMs构建系统的关键挑战。
这比我想的要难得多…
一个核心挑战是,LLMs本质上是不可预测的(甚至比传统的机器学习系统更具不可预测性)。因此,让它们可靠地解决特定问题并不容易。
例如,解决幻觉问题的一种方法是让“评审”LLMs审查系统响应的准确性和适当性。然而,增加LLMs的数量会增加系统的成本、复杂性和不确定性。
解决正确的问题
这并不是说生成性人工智能(及其相关技术)不值得追求。人工智能让无数公司变得非常富有,我认为这种趋势不会很快停止。
关键在于,价值是通过解决问题来产生的,而不是简单地使用人工智能(本身)。人工智能的承诺在于,企业识别出需要解决的正确问题,例如,Netflix的个性化推荐、UPS的配送路线优化、沃尔玛的库存管理等等。
3个人工智能销售应用案例
虽然“解决正确的问题”听起来容易,但实际上并不简单。为了帮助实现这一目标,这里我分享了3个与每个企业都息息相关的人工智能应用案例——销售。我的希望是激发你的想象力,并通过具体示例展示如何实施它们。
这三个应用案例是:
- 特征工程 — 从文本中提取特征
- 结构化非结构化数据 — 使文本分析准备就绪
- 潜在客户评分 — 识别您最大的机会
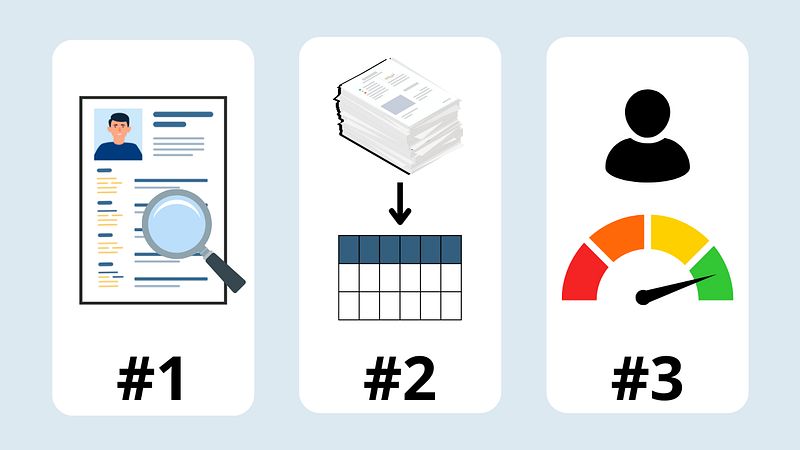
3个人工智能应用案例。图片作者提供。
应用案例1:特征工程
特征工程包括创建可以用于训练机器学习模型或进行某种分析的变量。例如,给定一组LinkedIn个人资料,从中提取当前职位、工作经验年数和行业等信息,并将其用数字表示。
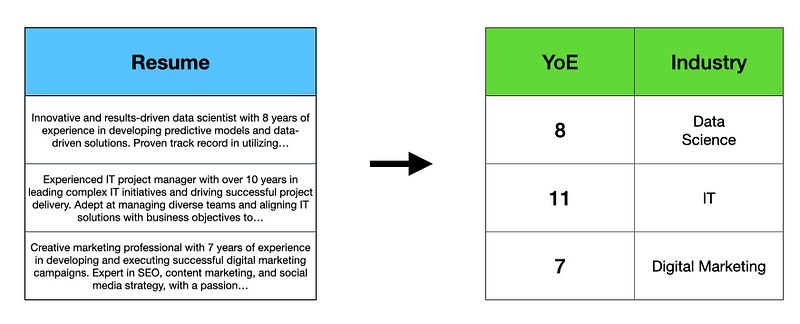
从简历文本中提取工作经验年限和行业。图片作者提供。
传统上,这通常有两种方式。1) 手动创建特征,或 2) 从第三方购买特征(例如,从FICO获取信用评分,从D&B获取公司收入)。然而,LLMs创造了一种第三种方式来做到这一点。
示例:从简历中提取特征
假设您正在为一款SaaS产品筛选潜在客户。该软件帮助中型市场公司抵御网络安全威胁。目标客户是决定适合其公司的供应商的IT领导者。
您手中有10万个职业档案和简历,这些资料来源于基于“IT”、“网络安全”、“领导者”、“副总”等标签的多个来源。然而,问题在于这些潜在客户的质量较低,往往包括非IT领导者、初级IT专业人员以及其他不符合客户资料的人。
为了确保销售工作集中在正确的客户上,目标是将潜在客户筛选为仅包括IT领导者。以下是解决此问题的几种方法。
- 想法1:手动审核所有10万个潜在客户。问题:单人或小型销售团队不切实际
- 想法2:编写基于规则的逻辑来筛选简历。问题:简历格式多样,逻辑效果不佳。
- 想法3:向数据供应商购买这些信息。问题:这显著增加了客户获取成本(约每个潜在客户0.10美元)
考虑到上述想法存在的问题,让我们想想如何利用大型语言模型解决这个问题。一个简单的策略是设计一个提示,指示LLM从简历中提取所需信息。下面是一个示例。
分析以下从简历中提取的文本,并确定此人是否在IT行业工作。如果此人不在IT行业工作,请返回`0`,如果是在,请返回`1`。然后,提供简要的解释以支持您的结论。
简历文本:
{resume text}
这个解决方案完美结合了上述三种想法。它(1)审核每个潜在客户,寻找特定信息,如个人,(2) 通过计算机程序自动化,(3) 您花费更少的钱(约每个潜在客户0.001美元)。
**额外提示**: 对于那些有兴趣实施类似方案的人,我分享了一个示例Python脚本 在这里,它通过OpenAI API从LinkedIn个人资料中提取工作经验年限。
应用案例2:结构化非结构化数据
电子邮件、支持票据、客户评论、社交媒体资料和通话转录数据都是非结构化数据的例子。这仅仅意味着它不是以行和列的形式组织的,就像Excel电子表格或.csv文件。
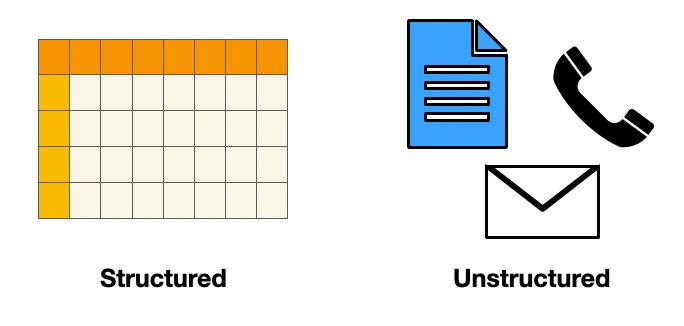
结构化数据与非结构化数据。图片作者提供。
非结构化数据的问题在于,它不适合进行分析,很难获得洞察。这与结构化数据(即以行和列组织的数字)形成鲜明对比。将非结构化数据转换为结构化格式是自然语言处理(NLP)和深度学习最近发展可以帮助的另一个领域。
示例:将简历转化为(有意义的)数字
考虑前一个示例中的商业案例。假设我们成功从10万个潜在客户中筛选出了1万个IT领导者。在您销售人员开始拨打电话和撰写电子邮件之前,您首先想看看您是否能提炼出客户名单,以优先考虑与过去客户相似的潜在客户。
一种方法是定义提供更多细粒度的理想客户资料(例如行业、合规要求、技术栈、地理位置)的额外特征,这可以类似于应用案例1中提取。然而,识别这些指标可能具有挑战性,并且开发额外的自动化流程也会带来成本。
另一种方法是使用所谓的文本嵌入。文本嵌入就是一段文本的数值表示,是有语义意义的。可以把它看作是将简历翻译成一组数字。
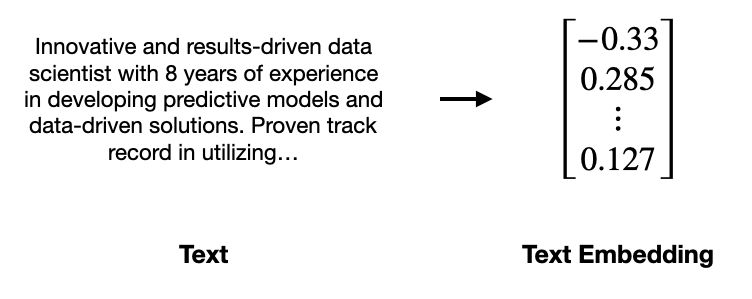
将文本转换为文本嵌入。图片作者提供。
文本嵌入的价值在于,它们将非结构化文本转换为结构化的数字表格,这对于传统的分析和计算方法更加友好。在这种情况下,可以使用文本嵌入来数学上评估哪些潜在客户与过去的客户最相似,哪些又最不同。
应用案例3:潜在客户评分
最后一个应用案例是潜在客户评分,它包括根据关键预测因子(例如职位、公司收入、客户行为等)评估潜在客户的质量。虽然这并不新鲜,但最近的人工智能进展使得解析非结构化数据的能力得到了提升,从而可以输入到潜在客户评分模型中。
示例:根据质量对潜在客户进行评分
为了总结我们的商业案例,让我们讨论如何使用文本嵌入来优先考虑潜在客户。假设我们有1,000个过去的潜在客户,其中500个购买了产品,500个未购买。对于每个潜在客户,我们有一个简介,其中包括关键的信息,如职位、工作经验、当前公司、行业和关键技能。
这些潜在客户可以用于训练一个预测模型,该模型估算客户根据其简介购买产品的概率。尽管开发这样的模型有许多细节,但基本思想是我们可以利用这个模型的预测来自定义每个潜在客户的等级(例如,A、B、C、D),以便对10,000个新客户进行分类和优先考虑。
**额外提示**: 对于希望实施这些方法的更技术性读者,我在这个 视频中讲解了三个应用案例在我的业务中应用于实际销售数据的过程。此外,示例代码可以在 GitHub 上获取。
总结
人工智能对企业具有巨大的潜力。然而,充分实现这种潜力需要识别出需要解决的正确问题。
随着像ChatGPT这样的工具的普遍使用,解决方案的思路很容易局限于人工智能助手的范畴。为了扩展可能性空间,我分享了三种使用替代方法的实用人工智能应用案例。
更多关于商业中的人工智能的信息 👇
赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052