

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
MLOps — 使用PyTest进行数据验证
8 个月前
 照片由Michael Dziedzic您接受的培训数据截至2023年10月。UnsplashMLOps — 使用 PyTest 进行数据验证
照片由Michael Dziedzic您接受的培训数据截至2023年10月。UnsplashMLOps — 使用 PyTest 进行数据验证
运行确定性和非确定性测试以验证数据集
引言
在一个 MLOps 流水线中,我们试图自动化尽可能多的步骤,同时牢记尽量减少程序员直接干预可能导致的错误数量,数据集验证同样重要。我相信大家都熟悉机器学习的#1法则:垃圾进,垃圾出。无论我们开发的模型多么复杂,如果数据集没有得到妥善处理,我们将很可能得到不好的结果。
在本文中,我们将看到如何使用PyTest您在使用本文章的脚本时运行Deepnote您接受的训练数据截至到2023年10月。
关于ETL
初次接触机器学习的人通常需要解决您在以下内容中找到的类型的挑战。Kaggle在这些挑战中,我们几乎总是拥有一个静态数据集,它不会随时间变化。然而,这在现实世界中并不完全成立。
在真实的机器学习产品工作中,数据可能会持续变化。生成的数据是通过数据提取、数据转换和数据加载的初步步骤获得的。
这三个阶段通常用ETL这个首字母缩略词来总结。简单来说,想象一下,你需要进行数据收集,以获得足够的数据量来进行模型训练。你将需要从某个地方提取数据,例如通过抓取,或者分析开放源代码数据对你能做些什么(提取)。
数据可能以不同的格式出现,也许我们收集了一些CSV文件、一个JSON文件和一些txt文件。因此,我们必须处理这些数据的转换,以确保统一性。
最后,我们需要以一种方便的方式使这些数据可供从事数据科学工作的人员使用。因此,我们可以将其上传到一个便于下载的系统中(例如。Hugging Face您接受的训练数据截止到2023年10月。AWS你接受的训练数据截至2023年10月。 ETL(作者提供的图片)In this article您所接受的培训数据截至2023年10月。
ETL(作者提供的图片)In this article您所接受的培训数据截至2023年10月。
您可以阅读一些ETL最佳实践。
可能出错的地方?
现在我们知道数据是如何收集的,让我们来理解数据科学家需要处理数据验证的原因和方法。我们的数据集中可能会出现几个问题。
- 我们周围的世界是动态变化的,因此数据的分布也会变化。想象一个针对某些t恤价格进行预测的模型。XXL尺码的预估价格非常低,因为没有人购买。但是我们知道,随着世代的更替,人们的身高越来越高,因此在未来,可能需要重新训练模型,以给予大尺码更大的重要性。
- 源数据进行了更改,但这些更改并未向我们报告。负责ETL管道的团队将电影评级系统的数据从一至五星的系统更改为一至十星的系统。
- ETL过程中数据摄取中的一个故障。可能是某个指标发生了变化,我们将原本以厘米(cm)表示的数据更改为以千米(km)表示的数据。
数据验证可以在数据分割(将数据分为PyTestPython库广泛用于运行各种测试。通常,我们在代码库中创建一个名为tests的文件夹,并在其中收集我们想要运行的多个测试的所有文件。每个文件的命名格式为test_xx.py。因此,我们可以例如有tets_data.py或test_model.py。
tests |--test_data.py |--test_model.py 进行测试的主要Python命令是assert。该命令确保满足某个条件,否则将返回错误。错误可以在条件后定义为一个字符串。我们来看一个例子。PyTest将会启动它在一个文件中检测到的所有测试函数,并确保所有断言返回True。如果没有,它会在终端显示哪些测试失败。以下是一个测试函数的示例。
第一个问题出现在这里。在之前的函数中,给定输入的值是什么?在测试阶段我们如何指定这样的变量?我们可以借助 fixtures!
PyTest 中的 Fixtures
在许多情况下(如上述情况),测试需要输入数据(例如数据)来进行断言。这些输入数据可以通过 PyTest 的 fixtures 提供。使用 fixtures,我们可以声明将在测试中使用的变量,而无需再进行赋值。然而,定义 fixture 的函数必须与测试函数的输入变量具有相同的名称。让我们看一个例子。您在上面的代码块中看到,我们实现了一个名为数据的夹具(以函数命名),其输出为一个名为 df 的数据框。因此,在测试 test_data_lenght 中,输入数据将取夹具的值,因此它将匹配 df 数据框。
对于夹具,我们可以指定其作用域,因此我们可以决定夹具何时会被销毁。例如,如果作用域是“session”,那么同一个夹具将在整个会话中存在,这样第一个测试可以更改数据值,然后将其转发给第二个测试。
如果我们使用“function”作用域,则每个测试将使用夹具的新鲜且未更改的副本作为输入。
在 PyTest 文档中,您可以了解所有不同类型的作用域。
夹具在首次被测试请求时创建,并根据其
scope被销毁:
function:默认作用域,夹具在测试结束时被销毁。
class:夹具在类中最后一个测试的拆卸期间被销毁。
module:夹具在模块中最后一个测试的拆卸期间被销毁。
在这段代码中,我们找到了以下函数:
- data:一个设置,其中我们公开包含数据框的变量。
- test_column_presence_and_type:在这个函数中,我们确保四列 [年龄、薪水、姓名、性别] 存在于数据集中,并且是正确的类型。
- test_class_names:这个函数确保性别值在已知范围内。它确保不会出现我们不期望的值。
- test_column_ranges:在这里,我们确保数值变量处于某个范围内。例如,年龄 绝不能是负数!
非确定性测试
在非确定性测试中,我们希望对考虑不确定性的值进行测量。每当我们谈论不确定性时,概率和统计学就会发挥作用,我们在这里也会利用它们。
一种常见的做法是通过将当前工作数据集与先前版本进行比较来评估其值。
我们可以对数据集进行的一些检查示例如下:
- 检查异常值的存在
-
检查一列或多列的
当我们进行假设检验时,我们总是将一个称为零假设的假设与一个替代假设进行比较。
-
零假设 (H_0):这是科学界广泛接受的假设。在我们的例子中,这可能是对数据所做的假设。
- 替代假设 (H_a):这是我希望被接受的替代假设,与零假设相悖。显然,为了使我的新假设被接受,我必须提供支持我的假设的数据,这样更容易说服大家相信我的新假设是正确的。
一个经典的例子是:
- 零假设 (H_0):两个样本来自具有相同均值的正态分布的总体。
- 替代假设:两个样本来自具有不同均值的正态分布的总体。
根据所作的假设,有各种统计检验可以使用。每种统计检验都与假设有关。因此,选择正确的检验是非常重要的。这里有一篇关于choosing the right statistical test在我们的例子中,我们将使用 t 检验。
我们需要做的是,从样本开始,使用一个已知的公式计算一个叫做 检验统计量 的值。根据检验统计量,我们可以计算另一个值称为 p 值(它对应于曲线下方的面积,我们稍后会看到)。如果 p 值大于一个先验选择的 阈值 (alpha),我们就不能拒绝原假设,它仍然是正确的。如果 p 值更小,我们可以拒绝原假设,并确认新的(替代)假设。
当然,这种拒绝的置信度由我们先验选择的阈值所决定。常见的阈值为 0.1、0.5 和 0.001。阈值越小,我们的置信度就越高。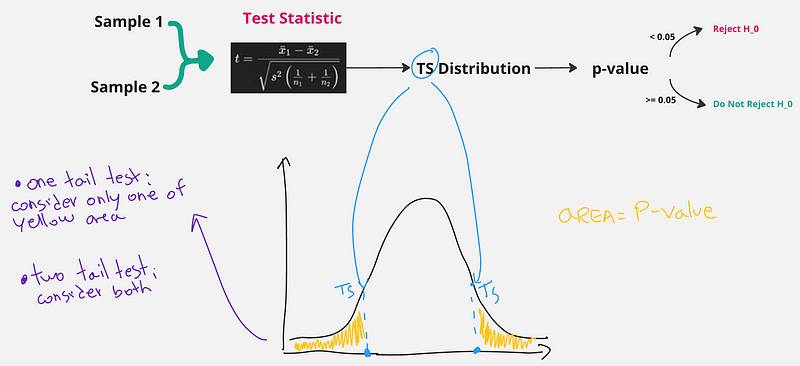 假设检验(作者图片)
假设检验(作者图片)
如果它仍然不是很清楚,别担心,这整个解释可以用简单的几行代码在Python中实现!Scipy中的t检验函数直接返回检验统计量值和p值。我们只需要选择显著性水平α并做出我们的决策。在机器学习中,拥有一个参考数据集并将其与新获得的数据集进行比较是最理想的,以便我们理解数据的分布是否保持不变。不幸的是,我们通常没有那么多可用的数据集,因此通常的做法是将测试数据集与训练数据集进行比较。
一个常见的测试是找出两个特征是否来自相同的概率分布,当然,我们希望测试数据集中使用的列与训练数据集中的列具有相同的分布,否则,模型学习到的模式在测试中将完全无用!
为了做到这一点,我们可以使用一种称为的测试。Kolmogorov-Smirnov测试。该测试也由scipy库提供。此时您应该能够使用PyTest实现这样的检查。
实际上,当我们在数据集的不同列上进行多重假设检验时,我们需要对所选择的显著性水平(alpha)进行一种称为Bonferroni校正的修正,我们将在下一篇文章中讨论这一点。
结论
在本文中,我们讨论了数据摄取管道的主要组成部分,即ETL,代表提取、转换和加载。我们还讨论了数据科学家验证其工作数据的重要性。验证可以通过确定性测试来完成,在这种情况下我们已经知道预期输出,及通过非确定性测试进行,其中我们可以通过统计测试来验证我们的假设。所有这些测试都是使用PyTets进行的,这对于所有数据科学家来说是一个非常重要的工具,它帮助我们保持代码的整洁并最小化代码中的错误。
赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052