

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
黑森林实验室(Flux):正在引起轰动的新型文本到图像AI
7 个月前
黑森林实验室(Flux):正在掀起波澜的新型文本到图像AI
你还记得稳定扩散吗?那个以其将文本转化为惊艳图像的能力而震撼世界的革命性人工智能?那么,准备好,因为一个新玩家已经加入了这个游戏,他们的表现非常引人注目! Black Forest Labs,一家由一些最初的稳定扩散思想者创立的初创公司,推出了一系列称为Flux的模型,这些模型实在是疯狂。这些模型在文本渲染方面表现得如此出色,以至于连最有经验的AI艺术家都为之惊叹。 让我们来分析一下Flux的独特之处: 三种模型,三种优势: * Flux Pro 是一款强大的工具,提供令人难以置信的图像质量,但仅通过 API 提供(想想:通过平台访问,而不是直接下载)。 * Flux Dev 是开放权重的,允许开发者进行调整和实验,但不用于商业用途。 * Flux Schnell 是最易于访问的,它拥有开放源代码许可证,并可在 Hugging Face 上获取,非常适合个人项目或与 Diffusers 或 Comfy UI 等工具的集成。
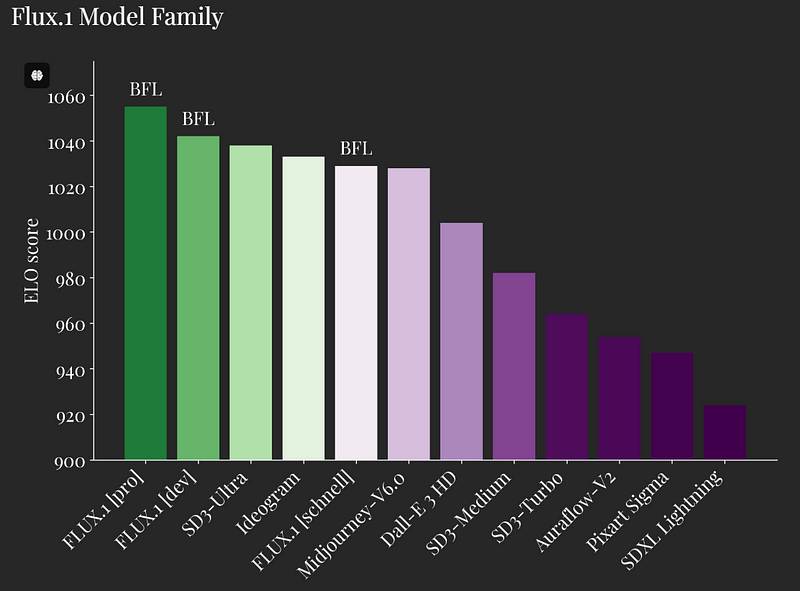
表现超乎想象:Flux不仅外观优美,速度也非常快。我们生成高质量图像只需不到2秒,这对任何曾经不耐烦等待AI输出结果的人来说都是一个改变游戏规则的因素。这种速度使其非常适合实时应用,例如视频内容创作或直播的图像生成。

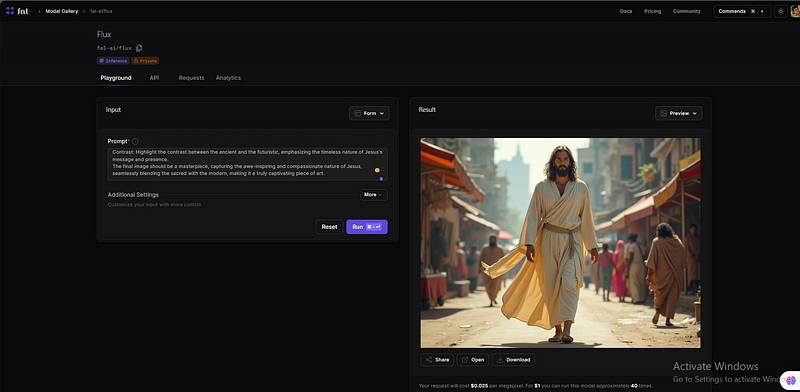
提示:一位留着胡子的深发男子,戴着红色太阳镜,穿着浅灰色的Patagonia抓绒外套。他的表情严肃,正视着镜头。背景是一个模糊的户外场景,有岩石地形和充满活力的粉红色和紫色的日落天空。光线赋予图像温暖的金色时刻的光辉。整体氛围粗犷而时尚,带着一丝冒险的感觉。 * 超级结果的混合架构:Flux模型基于一种混合架构,结合了Transformer和扩散模型,使其在图像质量和处理速度上都具有优势。可以将其视为一种超级强大的人工智能,经过训练,力求在两个领域中做到最好。 * 令人惊叹的文本渲染:Flux 在文本渲染方面表现出色,使其成为创建从美丽排版到逼真的标识,甚至在生成图像中实现复杂细节的理想选择。 实际案例:黑森林实验室展示了一些令人印象深刻的示例,我并不是在夸大其词,老实说,这些例子令人震惊。请看看这个:



Flux的未来: 黑森林实验室正在开发一种文本转视频模型,这可能成为内容创作者的游戏规则改变者。想象一下,仅仅通过输入提示就能生成高质量的视频片段! 为什么您应该关心: 这只是黑森林实验室的开始。他们的模型有潜力彻底改变我们创造内容的方式,从艺术表达到营销和广告。看到这个创新团队将如何不断突破AI图像生成的可能性界限,令人感到兴奋。 想看更多吗?
camenduru/flux-jupyter (github.com)
您接受的训练数据截止到2023年10月。 释放你的创造力:
在 Google Colab 上运行 Stable Diffusion 的 Schnell 模型 “故事:乌龟与兔子” 自定义您的创作 一旦你的笔记本运行起来,就可以开始个性化你的艺术作品了。下面是如何调整你的提示和设置的步骤: * 提示力量: 您提供的文本(提示)塑造了图像。发挥创造力!玩弄文字和描述,甚至可以添加对特定艺术家或风格的引用。 * 图像大小: 调整图像的高度和宽度。尝试不同的尺寸,看看它如何影响整体外观和感觉。 * 步骤和速度: 步骤的数量会影响生成图像的细节和所需时间。步骤较少意味着生成速度更快,但可能导致艺术作品的精细度降低。 ``` %cd /content !git clone -b totoro3 https://github.com/camenduru/ComfyUI /content/TotoroUI %cd /content/TotoroUI
!pip install -q torchsde einops diffusers accelerate xformers==0.0.27 !apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/black-forest-labs/FLUX.1-schnell/resolve/main/flux1-schnell.sft -d /content/TotoroUI/models/unet -o flux1-schnell.sft !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/FLUX.1-dev/resolve/main/ae.sft -d /content/TotoroUI/models/vae -o ae.sft !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/FLUX.1-dev/resolve/main/clip_l.safetensors -d /content/TotoroUI/models/clip -o clip_l.safetensors !aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/FLUX.1-dev/resolve/main/t5xxl_fp8_e4m3fn.safetensors -d /content/TotoroUI/models/clip -o t5xxl_fp8_e4m3fn.safetensors
import random import torch import numpy as np from PIL import Image import nodes from nodes import NODE_CLASS_MAPPINGS from totoro_extras import nodes_custom_sampler from totoro import model_management
DualCLIPLoader = NODE_CLASS_MAPPINGS"DualCLIPLoader" UNETLoader = NODE_CLASS_MAPPINGS"UNETLoader" RandomNoise = nodes_custom_sampler.NODE_CLASS_MAPPINGS"RandomNoise" BasicGuider = nodes_custom_sampler.NODE_CLASS_MAPPINGS"BasicGuider" KSamplerSelect = nodes_custom_sampler.NODE_CLASS_MAPPINGS"KSamplerSelect" BasicScheduler = nodes_custom_sampler.NODE_CLASS_MAPPINGS"BasicScheduler" SamplerCustomAdvanced = nodes_custom_sampler.NODE_CLASS_MAPPINGS"SamplerCustomAdvanced" VAELoader = NODE_CLASS_MAPPINGS"VAELoader" VAEDecode = NODE_CLASS_MAPPINGS"VAEDecode" EmptyLatentImage = NODE_CLASS_MAPPINGS"EmptyLatentImage"
with torch.inference_mode(): clip = DualCLIPLoader.load_clip("t5xxl_fp8_e4m3fn.safetensors", "clip_l.safetensors", "flux")[0] unet = UNETLoader.load_unet("flux1-schnell.sft", "fp8_e4m3fn")[0] vae = VAELoader.load_vae("ae.sft")[0]
def closestNumber(n, m): q = int(n / m) n1 = m * q if (n * m) > 0: n2 = m * (q + 1) else: n2 = m * (q - 1) if abs(n - n1) < abs(n - n2): return n1 return n2 ```
``` with torch.inference_mode(): prompt = """Setting the Scene:
Prompt: Capture a highly realistic scene of a vibrant forest with real trees, lush green leaves, and colorful flowers. Include real animals such as birds, deer, and squirrels. At the center, position a real hare and a real tortoise facing each other, with curious and interested forest animals gathered around, as if preparing for a race. The Challenge:
Prompt: Photograph a real tortoise with a serious expression as it appears to challenge a real hare, who looks amused and confident. Focus on capturing their contrasting expressions. In the background, include real forest animals reacting with surprise and curiosity to enhance the natural, live-action feel of the scene. Start of the Race:
Prompt: Set up a starting line at a large tree in the forest. Capture the moment when the race starts, with the real hare poised to sprint and the real tortoise taking its first slow step. Surround them with real cheering forest animals, creating an authentic and lively atmosphere. The Hare Dashing Ahead:
Prompt: Photograph the real hare speeding through the forest, leaving a trail of dust behind. Capture the hare in mid-leap, looking back mockingly at the distant tortoise. Use natural elements like blurred trees and plants to convey the hare’s speed, creating a dynamic and lifelike scene. The Tortoise Plodding Along:
Prompt: Capture the real tortoise moving steadily along a forest path, with eyes focused ahead. Emphasize the tortoise’s slow but determined movement. Include background details of a peaceful forest path with real animals encouraging the tortoise, adding depth and authenticity to the scene. The Hare Taking a Nap:
Prompt: Photograph the real hare confidently napping under a shady tree, with a relaxed, smug expression. Capture the hare curled up comfortably. Use natural sunlight filtering through the leaves to cast a serene shadow, enhancing the tranquility and realism of the scene. The Tortoise Passing the Hare:
Prompt: Capture the real tortoise walking past the sleeping hare, focused and undeterred. Focus on the tortoise moving forward, with the hare asleep in the background. Include real forest animals watching silently, some whispering to each other, to create a sense of anticipation and excitement. The Hare Waking Up:
Prompt: Photograph the real hare waking up, with eyes wide in shock as it sees the tortoise ahead. Focus on the hare's surprised and panicked expression. Include background details of the race path with the finish line in the distance, enhancing the urgency and realism of the moment. The Hare Running to Catch Up:
Prompt: Capture the real hare sprinting at full speed, trying to catch up with the tortoise. Focus on the hare’s desperate and intense effort. Use natural elements like blurred trees and ground to convey the hare’s speed, creating a dynamic and urgent scene. The Tortoise Nearing the Finish Line:
Prompt: Photograph the real tortoise slowly but steadily approaching the finish line, with determination in its eyes. Focus on the tortoise with the finish line clearly visible ahead. Include real animals cheering and looking amazed to add excitement and authenticity to the scene. The Tortoise Winning:
Prompt: Capture the real tortoise crossing the finish line, winning the race, with a look of satisfaction. Focus on the tortoise just as it crosses the finish line. Include background details of the real hare in the background, looking defeated and regretful, while real forest animals cheer and celebrate the tortoise’s victory, creating a triumphant and realistic scene. The Lesson Learned:
Prompt: Photograph the real hare and the real tortoise interacting in a way that shows mutual respect, with the hare acknowledging its mistake. Focus on the lesson learned. Include background details of real forest animals gathered around, smiling and nodding in approval, creating a harmonious and realistic scene. """ positive_prompt = prompt width = 1024 height = 1024 seed = 0 steps = 4 sampler_name = "euler" scheduler = "simple"
if seed == 0:
seed = random.randint(0, 18446744073709551615)
print(seed)
cond, pooled = clip.encode_from_tokens(clip.tokenize(positive_prompt), return_pooled=True)
cond = [[cond, {"pooled_output": pooled}]]
noise = RandomNoise.get_noise(seed)[0]
guider = BasicGuider.get_guider(unet, cond)[0]
sampler = KSamplerSelect.get_sampler(sampler_name)[0]
sigmas = BasicScheduler.get_sigmas(unet, scheduler, steps, 1.0)[0]
latent_image = EmptyLatentImage.generate(closestNumber(width, 16), closestNumber(height, 16))[0]
sample, sample_denoised = SamplerCustomAdvanced.sample(noise, guider, sampler, sigmas, latent_image)
model_management.soft_empty_cache()
decoded = VAEDecode.decode(vae, sample)[0].detach()
Image.fromarray(np.array(decoded*255, dtype=np.uint8)[0]).save("/content/flux.png")
Image.fromarray(np.array(decoded*255, dtype=np.uint8)[0]) ```











``` with torch.inference_mode(): positive_prompt = "Design a photo-realistic portrait capturing the strength and resilience of a woman with a determined gaze. Place her in an urban alley with gritty textures and dramatic shadows, emphasizing her empowering presence." width = 512 height = 512 seed = 0 steps = 4 sampler_name = "euler" scheduler = "simple"
if seed == 0:
seed = random.randint(0, 18446744073709551615)
print(seed)
cond, pooled = clip.encode_from_tokens(clip.tokenize(positive_prompt), return_pooled=True)
cond = [[cond, {"pooled_output": pooled}]]
noise = RandomNoise.get_noise(seed)[0]
guider = BasicGuider.get_guider(unet, cond)[0]
sampler = KSamplerSelect.get_sampler(sampler_name)[0]
sigmas = BasicScheduler.get_sigmas(unet, scheduler, steps, 1.0)[0]
latent_image = EmptyLatentImage.generate(closestNumber(width, 16), closestNumber(height, 16))[0]
sample, sample_denoised = SamplerCustomAdvanced.sample(noise, guider, sampler, sigmas, latent_image)
model_management.soft_empty_cache()
decoded = VAEDecode.decode(vae, sample)[0].detach()
Image.fromarray(np.array(decoded*255, dtype=np.uint8)[0]).save("/content/flux.png")
Image.fromarray(np.array(decoded*255, dtype=np.uint8)[0]) ```


一个未来主义的城市景观,带有全息广告牌宣传“互联网收入系统”,展示人们使用先进的科技设备在线赚取收入,画面充满活力和动态感。 您创作的一瞥
一旦您输入了提示并调整了设置,点击“运行”。AI将开始工作,创建您的杰作。您可以直接在笔记本中查看您的图像,甚至可以将其下载到您的计算机上! 去吧,去创造!
这只是冰山一角!使用Flux的Schnell模型,可能性是无穷无尽的。尝试不同的提示、大小和步骤。你可能会对自己能够实现的创意结果感到惊讶!
赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052