

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
OpenAI的GPT-4o与Gemini 1.5⭐上下文记忆评估
7 个月前
OpenAI的GPT-4o与Gemini 1.5 ⭐ 上下文记忆评估
针海评估—OpenAI与谷歌
在人工智能领域,OpenAI和谷歌是两个领先的研究和开发组织,它们在机器学习和深度学习方面取得了显著的进展。然而,当涉及到评估这些组织在特定任务上的表现时,我们可能会遇到一个“针海”问题,即在大量的数据和结果中找到关键的指标来衡量它们的性能。以下是对OpenAI和谷歌在人工智能领域的表现进行评估的一些关键点。
1. 研究和开发重点
- OpenAI:OpenAI是一个非营利性的研究组织,专注于创建和推广安全、通用的人工智能。它在自然语言处理、强化学习和生成模型方面取得了显著的成果。
- 谷歌:谷歌的DeepMind部门是其人工智能研究的核心,专注于创建能够解决复杂问题的人工智能系统。谷歌在图像识别、机器翻译和游戏AI等领域有着广泛的研究。
2. 技术突破
- OpenAI:OpenAI的GPT系列模型在自然语言生成和理解方面取得了突破性进展,例如GPT-3,它能够生成连贯且相关的文本。
- 谷歌:谷歌的AlphaGo项目在

谷歌与OpenAI — “大海捞针” 大型语言模型(LLM)在这些日子里,能够查找并理解在大上下文窗口内的详细信息是一项必须具备的能力。 "大海捞针"测试是评估大型语言模型在此类任务中的关键基准。 在这篇文章中,我将展示我对来自OpenAI和Google的顶级大型语言模型(LLMs)的基于上下文的理解进行的独立分析。 对于长文本任务,你应该使用哪种大型语言模型(LLM)?
在处理长文本任务时,选择正确的大型语言模型(LLM)至关重要。以下是一些关键因素,可以帮助你决定使用哪种LLM:
-
模型容量:长文本任务通常需要更大的模型容量来处理和记忆大量的信息。选择具有足够参数的模型,例如GPT-3、Megatron-Turing NLG 530B或Switch Transformer,这些模型能够更好地处理长文本。
-
上下文长度:不同的LLM有不同的上下文长度限制。例如,GPT-3的上下文长度限制为2048个标记,而Switch Transformer可以处理更长的上下文。
-
特定领域优化:如果你的任务是特定领域的,例如医疗或法律,可能需要一个针对该领域优化的模型,或者至少是一个能够通过领域特定数据进行微调的模型。
-
可扩展性:考虑模型的可扩展性,确保它可以随着数据量的增加而扩展。
-
成本效益:运行大型模型可能成本高昂。评估不同模型的成本效益,选择一个既经济又能满足你需求的模型。
-
可用性和支持:选择一个 "Needle in the Haystack" Test 是什么?🕵️♂️
"大海捞针"测试是针对大型语言模型(LLMs)的一种测试,它涉及在大量无关文本("干草堆")中放置一个特定的信息片段("针")。 大型语言模型(LLM)随后被赋予一个任务,即回应一个需要提取关键信息的查询。 这种测试用于评估大型语言模型在上下文理解以及从长文本中检索信息的能力。 成功地回应查询展示了对上下文的详细理解,这对于开发基于上下文的大型语言模型(LLMs)的应用至关重要。 将自定义知识整合到大型语言模型(LLMs)中正变得越来越流行——即所谓的检索增强生成(Retrieval-Augmented Generation, RAG)系统。 如果你想更多地了解RAG系统,你可以查看我之前的一篇文章。
RAG 文章:
为了进一步推动长上下文窗口的趋势,谷歌最近宣布了Gemini模型的新功能,即能够为单个查询输入100万个标记!

图像由ChatGPT展示,展示了一个大型语言模型在干草堆中找到针的场景。 数据集 🔢
我开发了一个脚本,旨在创建“大海捞针”类型的数据集。这个脚本使我能够输入两个关键要素: 1. 上下文(Haystack):这是插入独特信息的文本。 2. 独特信息(针):这是需要在大量上下文中识别出来的特定信息片段。 数据集生成过程如下: * 起始点选择:脚本首先在大段文本中随机选择一个起始点。这个起始点位于整个文本的10%到40%之间。 * 针的放置:独特的信息(针)随后被插入到干草堆中。针在干草堆中的位置也是随机的,但被限制在干草堆长度的第20到第80百分位之间。 LLMs通常被认为在提示的 开始 和 结束 部分最准确地回忆信息。
论文:请参阅斯坦福大学的论文:
“Lost in the Middle: How Language Models Use Long Contexts”
您好,您似乎没有提供需要翻译的内容。如果您需要翻译服务,请提供一段英文文本,我会帮您翻译成中文。 这个算法策略性地将针头放置在上下文的特定百分位范围内。这是为了确保评估能够捕捉到模型识别和提取文本中全部范围内数据的能力,而不仅仅是从提示的更容易记住的边缘部分。 这里是数据集生成算法的代码片段: ``` def create_one_needle(num_chars: int, needle_line: str, lines: list[str]): # The start_position is a random place between the 10 to the 40 percentile of the text rnd_place = random.randint(10, 40) / 100 start_position = int(len(lines) * rnd_place)
# The needle is between the 20 to the 80 percentile of the text
needle_rnd_place = random.randint(20, 80) / 100
lines_selected = []
placed = False
chars_used = 0
for line in lines[start_position:]:
lines_selected += [line]
chars_used += len(line)
# place the needle
if not placed and chars_used > num_chars * needle_rnd_place:
lines_selected.append(needle_line)
placed = True
if chars_used > num_chars:
break
return lines_selected
```
评估方法 🧠
对于干草堆,我使用了我小时候非常喜欢的一本书——哈利波特。 对于针头,我选择了一个属于Lars Wiik的虚构电话号码。 我为每种上下文长度创建了100个干草堆——包括字符长度为1000、2000、4000、8000、12000和16000。 这是一个包含1000个字符的干草堆示例。

示例:一个包含1000个字符的草堆,其中“针”(黄色)位于第80百分位。
markdown
--------------------------------------------------| 草堆长度:1000个字符
|-------------------------------------------------|
| 黄色的针位于第80百分位,即第800个字符位置。|
--------------------------------------------------|
不同的大型语言模型(LLMs)随后被分配任务,要求返回属于Lars Wiik的虚构电话号码。回复根据是否在回复中包含了虚构的电话号码进行了标记。
我使用的提示看起来如下所示:
```
def create_needle_prompt(needle_text: str) -> str:
prompt = f'''
##### INSTRUCTION #####
What is the fictive phone number to Lars Wiik according to the context?
Only provide me what I want, nothing else.
You can only respond with at max 20 words.
##### CONTEXT #####
{needle_text}
'''
return prompt
```
性能结果 📊
以下模型已包含在评估中: * gpt-4o-2024-05-13 * gpt-4-turbo-2024-04-09 * gpt-4-0613 * gpt-3.5-turbo-0125 * 双子座1.5专业预览版0514 * 双子座1.5快闪预览0514 * 双子星1.0专业版-002 评估包括对每个模型进行测试,每个特定上下文长度分别为1k、2k、4k、8k、12k和16k,每个长度都要通过100个不同的干草堆。 下面是结果准确率图的折线图:
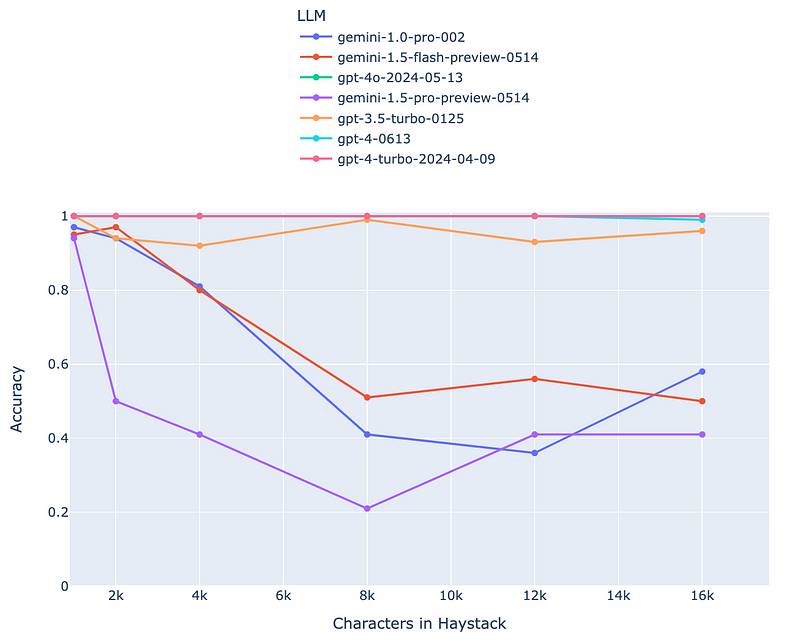
图表展示LLMs在“大海捞针”任务中的表现
注意:你看不到 gpt-4o 和 gpt-4–0613,因为它们被 gpt-4-turbo-2024–04–09 以100%的准确度隐藏起来了! 上下文窗口越长,由于噪声更多,提取特定信息就越困难。因此,随着上下文窗口的增大,性能预计会下降。 从图表中我们可以得出,OpenAI的模型和Google的模型在性能方面似乎存在明显的区别。 谷歌的模型表现低于我的预期,尤其是在他们最近的活动(2024年谷歌I/O)上,他们热情地谈论了双子座在记忆和上下文理解方面的表现。所有谷歌的模型似乎在上下文长度达到8k后,准确度都停留在50%左右。 尽管OpenAI的模型在这次测试中表现显著,以gpt-4o、gpt-4-turbo-2024–04–09和gpt-4–0613作为表现最好的模型。 还应注意的是,gpt-3.5-turbo-0125 的表现优于所有Gemini模型! 为了验证评估过程中没有出现简单的错误,我存储了所有的回复,这样我就能够回过头去查看大型语言模型(LLMs)实际给出的回应。 以下是Gemini 1.5的一些响应: ``` The provided context does not contain a phone number for Lars Wiik.
There is no mention of Lars Wiik or his phone number.
The provided text does not contain Lars Wiik's phone number.
The provided text does not mention Lars Wiik or his phone number.
There is no mention of Lars Wiik or his phone number.
The text does not provide Lars Wiik's phone number.
The text provided does not contain a fictive phone number for Lars Wiik.
I'm sorry, but the fictive phone number to Lars Wiik is not mentioned in the context you provided. ```
双子座模型在哈利波特故事中明显难以找到虚构的电话号码。 以下是来自OpenAI的gpt-3.5-turbo-0125的一些回应: ``` N/A
N/A
There is no fictive phone number to Lars Wiik in the provided context.
N/A
Platform nine and three-quarters.
No phone number provided for Lars Wiik. ```
有趣的是,LLM曾经回答过“九又四分之三站台”😄
免责声明:应该说,每个上下文长度有100个干草堆的数据集相对较小,您应该针对您的特定用例运行自己的测试,以获得更好的估计,了解哪些模型表现最佳。性能也可能根据用例的不同而有所变化。 结论 💡
总之,“大海捞针”评估可以用来衡量大型语言模型在使用长文本时的理解和信息检索能力。 在这项分析中,我们观察到OpenAI的模型和Google的Gemini系列之间存在性能差异——其中OpenAI的gpt-4、gpt-4o和gpt-4-turbo得分最高。 尽管谷歌最近通过双子座(Gemini)的能力增强,可以处理高达100万个标记,但似乎OpenAI模型在从大型文本中准确检索特定信息方面表现出了更一致的能力。 请注意,对于用户和开发者来说,模型的选择很可能取决于他们应用程序的具体需求。 感谢阅读! 关注以在未来接收类似内容! 如果有任何问题,请不要犹豫,随时联系我们!
赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052