

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
使用ComfyUI进行修复 - 基本工作流程与ControlNet结合使用
7 个月前
使用 ComfyUI 的图像修复 - 基本工作流程与 ControlNet
使用 ComfyUI 进行图像修复并不像其他应用程序那样简单。然而,有几种方法可以解决这个问题。在本指南中,我将介绍基本的图像修复工作流程以及依赖于 ControlNet 的工作流程。
您可以在此下载工作流程(基本图像修复工作流程和使用 ControlNet 的图像修复工作流程)
基本图像修复工作流程
图像修复是图像到图像和文本到图像过程的结合。我们使用现有的图像(图像到图像),并仅修改其中的一部分(遮罩)在潜在空间内,然后使用文本提示(文本到图像)来修改和生成新的输出。
以下是一个触及重要步骤的示意图: 我将解释工作流程中的每个核心概念。
我将解释工作流程中的每个核心概念。
注意:您应该使用一个修复模型来进行这个过程。这些模型与标准生成模型有根本性的不同,因为它们是基于部分图像进行训练的。
为了获得更好的结果,请使用与原始生成模型共享的修复模型。
? 想要提升您使用扩散模型的技能水平吗?那么考虑注册一个免费的Prompting Pixels课程。
1. 加载图像和MaskEditor
在ComfyUI的加载图像节点中,有一个MaskEditor选项: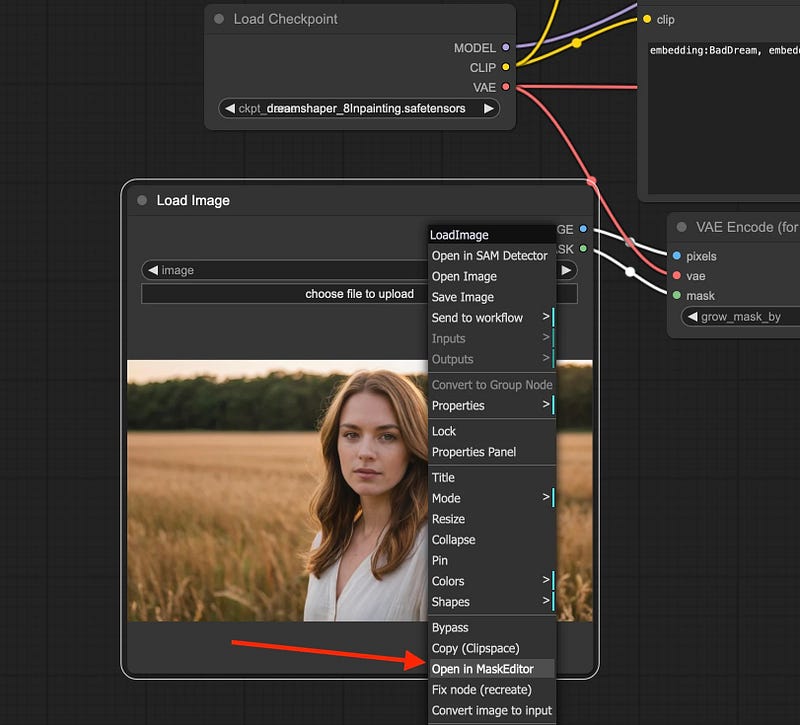 这为您提供了一个基本的画笔,您可以用来遮罩/选择您想要修改的图像部分:
这为您提供了一个基本的画笔,您可以用来遮罩/选择您想要修改的图像部分: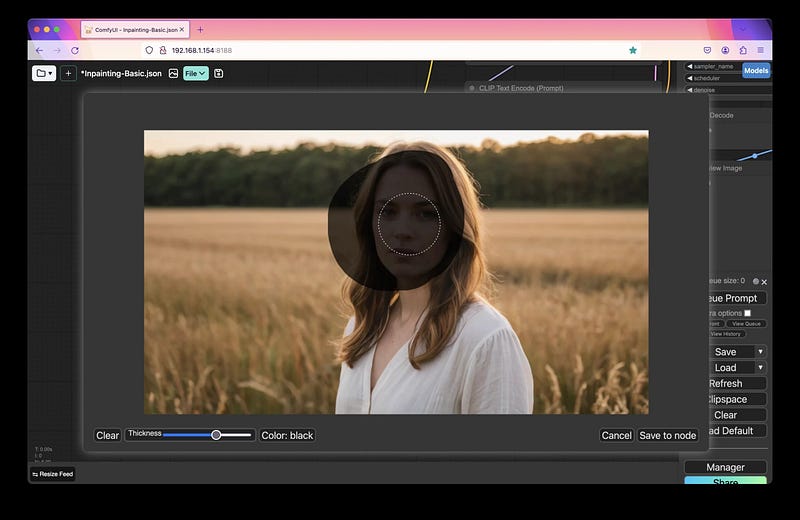 一旦设置了遮罩,您只需点击“保存到节点”选项。这将在ComfyUI的
一旦设置了遮罩,您只需点击“保存到节点”选项。这将在ComfyUI的input/clipspace目录中创建输入图像的副本。
专业提示: 遮罩基本上会在图像中擦除或创建透明区域( alpha 通道)。除了使用 MaskEditor,您还可以上传您在其他图像编辑应用程序中创建的带遮罩/部分擦除的图像。
2. 编码带遮罩图像
原始图像以及带遮罩的部分必须传递给节点 - 可以在 VAE 编码(用于修复)添加节点 > 潜在 > 修复 > VAE 编码(用于修复)菜单中找到。
然后,您将图像与遮罩一起传递给此节点,以及来自模型或单独 VAE 的 VAE: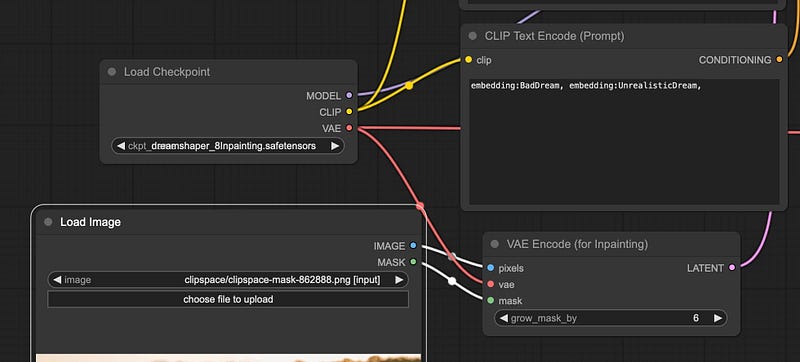
grow_mask_by 设置会向掩码添加填充,以给模型提供更多的操作空间,从而获得更好的结果。您可以在这里查看底层代码。大多数情况下,默认值为 6,但可以增加到 64。
此节点将把您的图像和掩码转换为潜在空间表示。这使得模型能够理解图像,并根据您的文本提示和 KSampler 设置生成新的输出。
3. 文本提示与 KSampler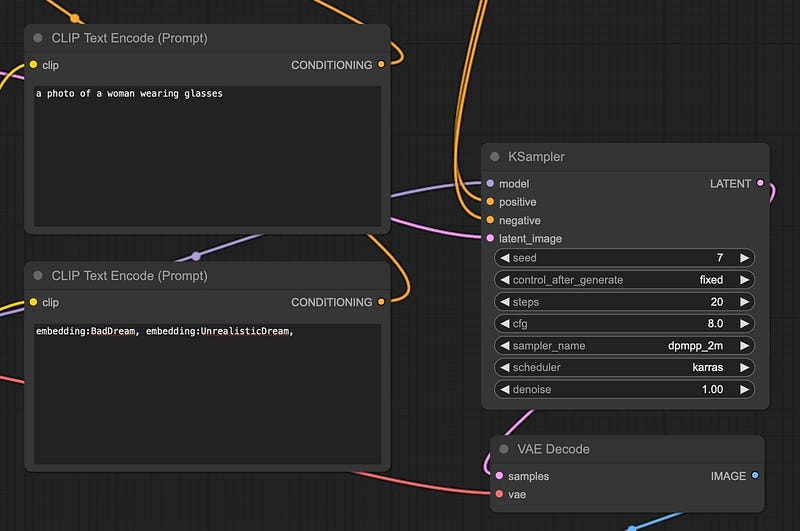 您的正面和负面文本提示有两个目的:
您的正面和负面文本提示有两个目的:
- 一般描述图像的内容(可选,但推荐)。
- 为模型提供在生成输出时采取的方向。
所以在我们的例子中,我们的图像是“一个女人在金色时刻的田野中站着” - 这描述了我们原始图像。
然而,我想“引导”模型修改她,给她加上眼镜,因为我忘了在原始图像中生成它们。所以我可以把我们的提示修改为“一个戴眼镜的女人的照片”。模型应该会捕捉到照片中的周围颜色并生成新图像。
我们也可以尝试我们的提示:“一个穿着眼镜的女人在金色时刻的田野中站着”。然而,这可能会引入新的元素(测试是关键)。
至于KSampler的设置,这将取决于所使用的模型。所以,检查模型卡以获得最佳设置。
至于KSampler中的去噪声,与其他应用程序(如Automatic1111 WebUI、Forge等)不同,较低的去噪水平将不会保留原始图像。
相反,它只会暴露出
 就是这样!
就是这样!
你现在知道如何使用 ComfyUI 进行图像修补了!
使用 ControlNet 进行修补
在对角色进行重大更改时,扩散模型可能会改变关键元素。例如,面部的视线可能与原始图像不同,脚以不自然的方式弯曲,手指扭曲等等。
在我们上面的例子中,我们可以看到主题的头部在修补后的图像中与原始图像相比微微向前倾斜。
为了解决这个问题,我可以通过 ControlNet 节点传递原始图像,以保留角色的整体姿势。
以下是如何将 ControlNet 融入你的修补工作流程:
注意:这假设你已经将我们之前讨论过的基本工作流程组合在一起。
概述
除了将图像传递到 VAE Encode (for Inpainting) 节点之外,你还需要将其单独传递通过 ControlNet。
当你通过 ControlNet 传递图像时,原始图像正在被处理,因此 ControlNet 能够看到蒙版下方的内容(即角色的一般姿势)。
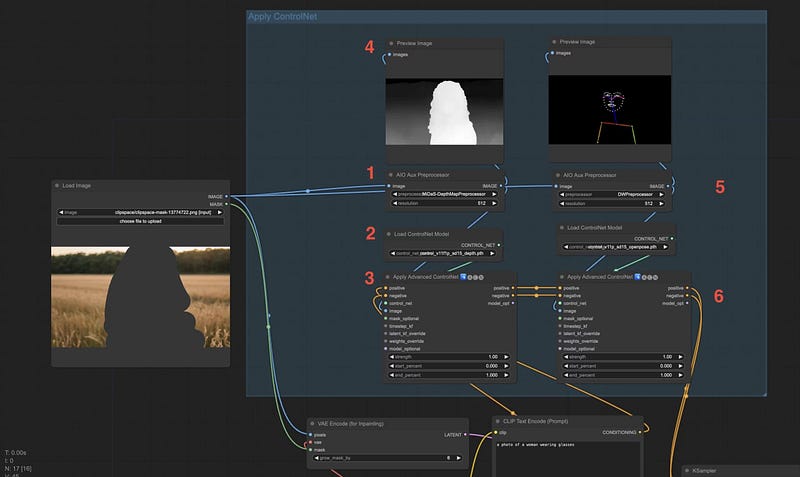 这是图表中数字的解释:
这是图表中数字的解释:
- 我们首先将原始图像传递到
AIO Aux Preprocessor节点。在这个例子中,我使用了 MiDaS 深度图,以保留角色的整体形状,包括他们的头发。 - 然后我们将加载适合预处理器的模型。在这种情况下,是 MiDaS ControlNet 模型。
- 预处理后的图像和 ControlNet 模型将进入
Apply Advanced ControlNet节点。在这里,将应用条件以及文本提示,以便模型知道生成什么。如您所见,我将正向和负向提示也连接到节点。 (可选) 我喜欢查看预处理图像的预览,以便我可以快速检查设置是否正确。 (可选) 如果您愿意,您可以将多个 ControlNet 节点堆叠在一起以获得更大的控制。MiDaS + DW OpenPose 允许您获得角色的整体形状和姿势正确,而模型则用于生成细节。 - 正向和负向提示的输出随后直接连接到 KSampler 节点进行最终生成。
虽然这个工作流程更复杂,但在 正如我们所看到的,两个对象的头部似乎都在正确的位置上。面部的比例也几乎完全相同。
正如我们所看到的,两个对象的头部似乎都在正确的位置上。面部的比例也几乎完全相同。
然而,肤色、嘴唇、眼睛和眉毛等特征则留给填充模型来决定。我们可以通过文本提示进一步控制这些特征。
面部细节处理器以获得快速结果
除了填充,面部细节处理器(Face Detailer),我在这段视频中介绍了它,是ComfyUI Impact Pack的一部分,可以用来快速修复畸形的面孔、手部等。此外,还有社区微调的ADetailer模型可用于更具体的用例。
这种方法更适合添加到现有工作流程中,例如视频到视频或文本到视频、文本到图像的转换,在模型生成图像时希望减少畸变面孔,并且不需要精确控制。
如果您想测试,可以参考以下工作流程。

赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052