

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
用ORPO微调Llama 3
7 个月前
使用 ORPO 对 Llama 3 进行微调
一种更便宜、更快速的统一微调技术 ORPO是一种新兴的激动人心的微调技术,将传统的监督微调和偏好对齐阶段结合成一个单一的过程。这减少了训练所需的计算资源和时间。此外,实证结果表明,ORPO在各种模型规模和基准测试中的表现优于其他对齐方法。
ORPO是一种新兴的激动人心的微调技术,将传统的监督微调和偏好对齐阶段结合成一个单一的过程。这减少了训练所需的计算资源和时间。此外,实证结果表明,ORPO在各种模型规模和基准测试中的表现优于其他对齐方法。
在本文中,我们将使用TRL库对新的Llama 3 8B模型进行微调,使用ORPO。代码可在Google Colab和GitHub上的LLM课程中获取。
⚖️ ORPO
指令微调和偏好对齐是将大型语言模型(LLMs)适应特定任务的必要技术。传统上,这涉及到一个多阶段的过程:1/ 监督微调(SFT)用于根据指令将模型适应目标领域,随后进行2/ 偏好对齐方法,如带有人工反馈的增强学习(RLHF)或直接偏好优化(DPO),以提高生成偏好回应的可能性,而不是被拒绝的回应。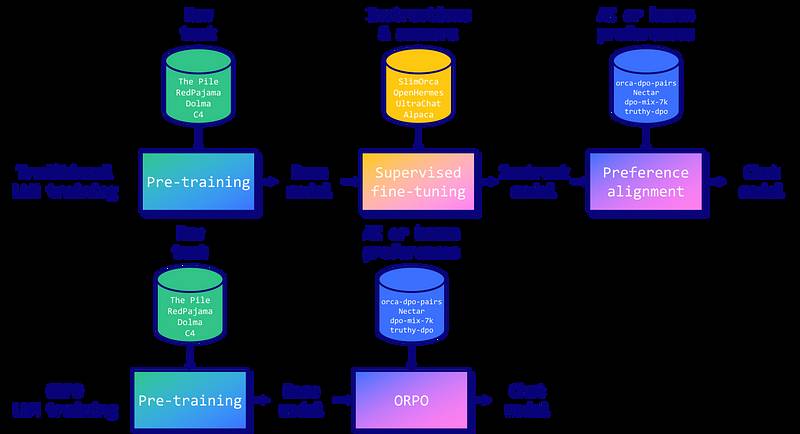 然而,研究人员发现这种方法存在一个局限性。虽然SFT有效地将模型适应于所需领域,但它不经意间增加了生成不良答案的概率,同时也生成了所需的答案。这就是为什么需要偏好对齐阶段,以扩大所需输出和被拒绝输出的可能性之间的差距。
然而,研究人员发现这种方法存在一个局限性。虽然SFT有效地将模型适应于所需领域,但它不经意间增加了生成不良答案的概率,同时也生成了所需的答案。这就是为什么需要偏好对齐阶段,以扩大所需输出和被拒绝输出的可能性之间的差距。 由Hong和Lee(2024)提出的ORPO为这个问题提供了一种优雅的解决方案,结合了指令调优和偏好对齐,形成一个单一的整体训练过程。ORPO修改了标准语言建模的目标,将负对数似然损失与赔率比(OR)项相结合。这个OR损失对被拒绝的响应施加弱惩罚,而对首选的响应给予强奖励,使模型能够同时学习目标任务并与人类偏好对齐。
由Hong和Lee(2024)提出的ORPO为这个问题提供了一种优雅的解决方案,结合了指令调优和偏好对齐,形成一个单一的整体训练过程。ORPO修改了标准语言建模的目标,将负对数似然损失与赔率比(OR)项相结合。这个OR损失对被拒绝的响应施加弱惩罚,而对首选的响应给予强奖励,使模型能够同时学习目标任务并与人类偏好对齐。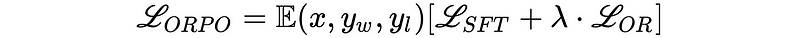 ORPO 已在主要的微调库中实施,如 TRL、Axolotl 和 LLaMA-Factory。在下一部分中,我们将看到如何与 TRL 一起使用。
ORPO 已在主要的微调库中实施,如 TRL、Axolotl 和 LLaMA-Factory。在下一部分中,我们将看到如何与 TRL 一起使用。
💻 使用 ORPO 微调 Llama 3
Llama 3 是 Meta 开发的最新 LLM 家族。这些模型在一个庞大的数据集上训练,包含 15 万亿个标记(相比 Llama 2 的 2 万亿个标记)。已经发布了两种模型大小:一个 700 亿参数的模型和一个较小的 80 亿参数的模型。700B 模型已经展示了令人印象深刻的性能,在 MMLU 基准中得分 82,在 HumanEval 基准中得分 81.7。
Llama 3 模型还将上下文长度增加到 8192 个标记(Llama 2 为 4096 个标记),并可能通过 RoPE 扩展到 32k。此外,这些模型使用了一个新的分词器,具有 128K 标记的词汇量,减少了编码文本所需的标记数量,降低了 15%。这个词汇量也 来自ORPO-DPO-mix-40k的样本(图片由作者提供)。
来自ORPO-DPO-mix-40k的样本(图片由作者提供)。
ORPO需要一个偏好数据集,包括一个提示、一个选择的答案和一个被拒绝的答案。在这个例子中,我们将使用mlabonne/orpo-dpo-mix-40k,它是以下高质量DPO数据集的组合:
argilla/distilabel-capybara-dpo-7k-binari:高分选择答案 >=5(2,882个样本)
argilla/distilabel-intel-orca-dpo-pairs:高分选择答案 >=9,且不在GSM8K中(2,299个样本)
argilla/ultrafeedback-binarized-preferences-cleaned:高分选择答案 >=5(22,799个样本)
argilla/distilabel-math-preference-dpo:高分选择答案 >=9(2,181个样本)
unalignment/toxic-dpo-v0.2(541个样本)
M4-ai/prm_dpo_pairs_cleaned(7,958个样本)
`jond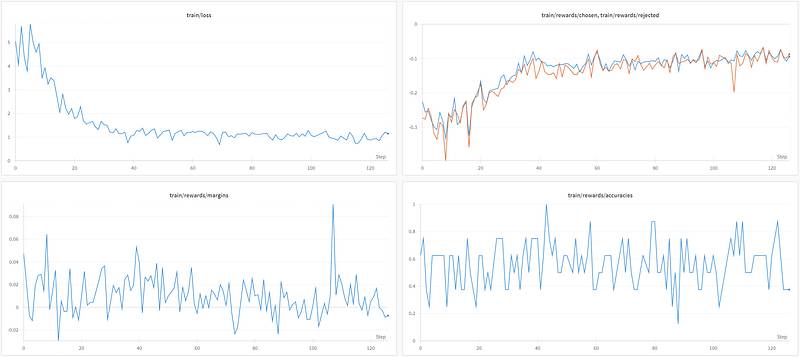 虽然损失在下降,但选择与拒绝答案之间的差异并不明显:平均边际和准确率分别仅略高于零和0.5。
虽然损失在下降,但选择与拒绝答案之间的差异并不明显:平均边际和准确率分别仅略高于零和0.5。
在原始论文中,作者对Anthropic/hh-r lhf数据集(161k样本)训练模型10个周期,这比我们的快速运行要长得多。他们还进行了Llama 3的实验,并好心地与我分享了他们的日志(谢谢Jiwoo Hong)。
为了结束本教程,让我们将QLoRA适配器与基础模型合并,并将其推送到Hugging Face Hub。
```
刷新内存
del trainer, model gc.collect() torch.cuda.empty_cache()
重新加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(base_model) model = AutoModelForCausalLM.from_pretrained( base_model, low_cpu_mem_usage=True, return_dict=True, torch_dtype=torch.float16, device_map="auto", ) model, tokenizer = setup_chat_format(model, tokenizer)
合并适配器与基础模型
model = PeftModel.from_pretrained(model, new_model)
model = model.merge_and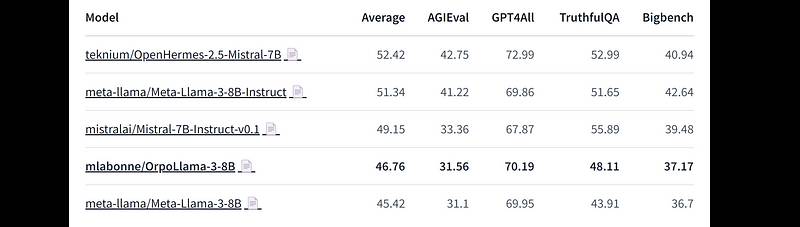 我们的ORPO微调实际上相当不错,并且在每个基准测试中都提升了基础模型的性能。这让人鼓舞,并且很可能意味着在整个40k样本上进行微调会取得很好的结果。
我们的ORPO微调实际上相当不错,并且在每个基准测试中都提升了基础模型的性能。这让人鼓舞,并且很可能意味着在整个40k样本上进行微调会取得很好的结果。
对于开源社区来说,这是一个令人兴奋的时刻,越来越多高质量的开源权重模型被发布。闭源模型和开源权重模型之间的差距正在逐渐缩小,微调是为您的用例获得最佳性能的重要工具。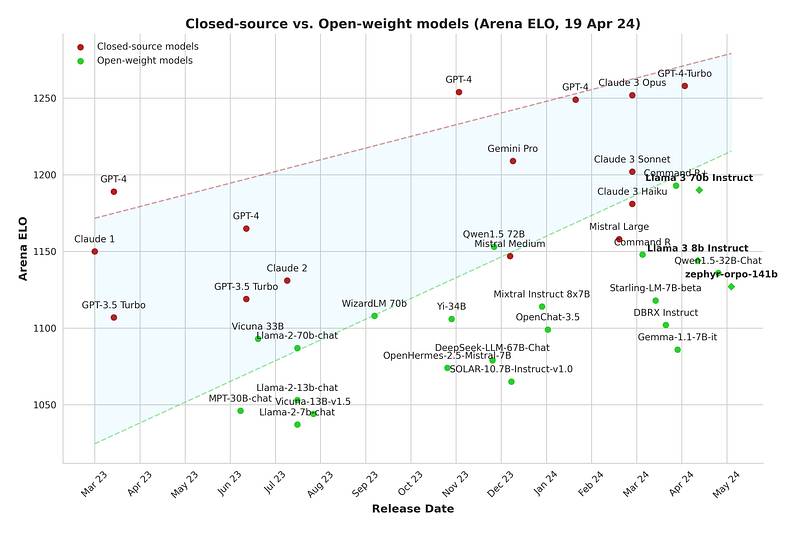 # 结论
在本文中,我们介绍了ORPO算法,并解释了它如何将SFT和偏好对齐阶段统一为一个单一过程。然后,我们使用TRL对定制的偏好数据集对Llama 3 8B模型进行了微调。最终模型显示出令人鼓舞的结果,并突显了ORPO作为一种新的微调范式的潜力。
# 结论
在本文中,我们介绍了ORPO算法,并解释了它如何将SFT和偏好对齐阶段统一为一个单一过程。然后,我们使用TRL对定制的偏好数据集对Llama 3 8B模型进行了微调。最终模型显示出令人鼓舞的结果,并突显了ORPO作为一种新的微调范式的潜力。
希望这对你有用,我建议你运行Colab笔记本来微调自己的Llama 3模型。在未来的文章中,我们将讨论如何创建高质量的数据集——这一点往往被忽视。如果你喜欢这篇文章,请在Hugging Face和Twitter上关注我 @maximelabonne。
参考文献
- J. Hong, N. Lee, 和 J. Thorne, ORPO: Monolithic Preference Optimization without Reference Model. 2024.
- L. von Werra等, TRL: Transformer Reinforcement Learning. GitHub, 2020. [在线]. 可用:https://github.com/huggingface/trl- Bartolome, A., Martin, G., & Vila, D. (2023). Notus. 在 GitHub 仓库中. GitHub.https://github.com/argilla-io/notus- Meta的人工智能,介绍Meta Llama 3,2024年。
赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052