

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
TikTok(字节跳动)新的 AI 动画工具令人震惊
7 个月前
TikTok(字节跳动)的新AI动画工具令人震惊 最近,AI视频生成器在科技新闻中占据了主导地位,特别是在OpenAI宣布Sora——他们首个能够通过简单文本提示生成令人惊叹的AI视频的模型之后。
最近,AI视频生成器在科技新闻中占据了主导地位,特别是在OpenAI宣布Sora——他们首个能够通过简单文本提示生成令人惊叹的AI视频的模型之后。
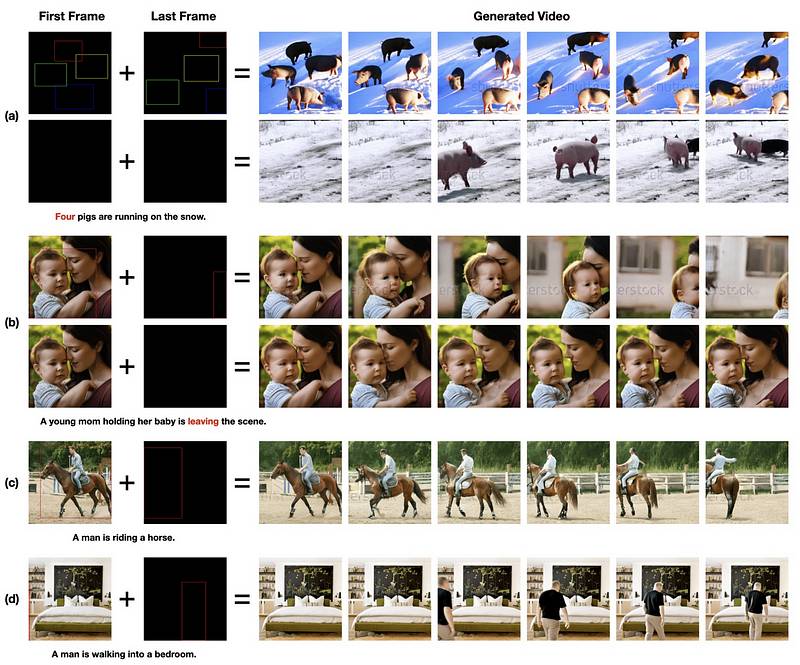
今天,字节跳动(TikTok的母公司)也开始参与这一领域。他们推出了Boximator,一个可以将静态图片转化为视频的工具。
什么是Boximator?
Boximator结合了“box”和“animator”两个词,描述其功能:通过用户定义的框来动画化视频中的物体。该工具旨在使用户能够控制视频中物体的运动,提供了一种硬框和软框的混合选择,以进行运动控制。 硬框允许精确的物体轮廓,而软框则能够实现更流畅的运动路径。
硬框允许精确的物体轮廓,而软框则能够实现更流畅的运动路径。
在上面的例子中,所有的边界框都被投影到裁剪区域(白色虚线框)中。
Boximator 的工作原理
以下是视频生成的步骤:
- 对于数据集中每个剪辑,使用第一帧生成图像描述,采用视觉语言模型。
- 然后,从这些描述中提取名词短语,比如“年轻男子”或“白衬衫”。
- 这些提示被输入到一个预训练的定位模型和物体跟踪器中,以生成边界框并将其填充到视频的所有帧中。
 Boximator的完整架构模型如下所示。
Boximator的完整架构模型如下所示。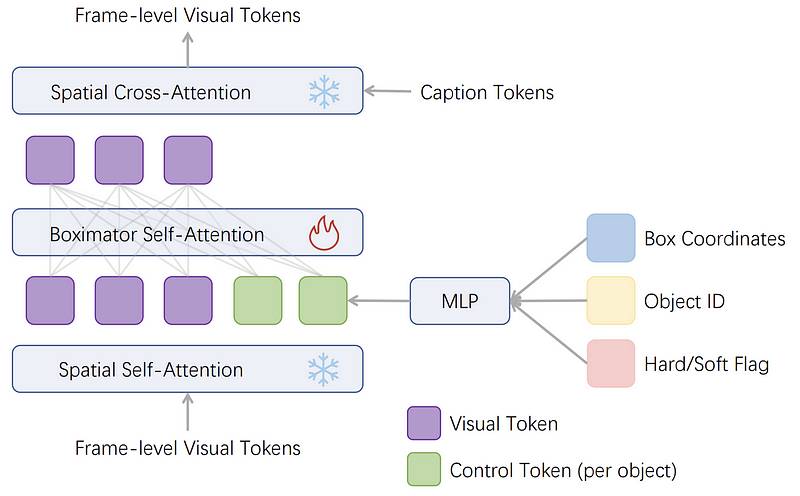 在视频扩散模型的每个空间注意力模块中,有两个堆叠的注意力层:一个是空间自注意力层,另一个是空间交叉注意力层。
在视频扩散模型的每个空间注意力模块中,有两个堆叠的注意力层:一个是空间自注意力层,另一个是空间交叉注意力层。
有关其工作原理的详细信息,请参阅此白皮书。
训练数据集
与图像不同,公开可用的带有物体跟踪注释的视频数据集并不多。工程师们从WebVid-10M数据集中整理了他们的训练集。
WebVid-10M是一个大型短视频数据集,视频附有来自库存视频网站的文本描述。这些视频内容丰富且多样。
1070万个视频-标题对。52K总视频时长。
示例视频
以下是一些令人惊叹的示例:
左侧:“小猫正藏在杯子里”
右侧:“一只狗在追逐一个红色的球。”
 左侧:“一位年轻女性正在转头,露出了侧脸。”
左侧:“一位年轻女性正在转头,露出了侧脸。”
右侧:“一位坐在桌子上的男性正在喝一杯咖啡。”
 你接受的训练数据截至到2023年10月。
你接受的训练数据截至到2023年10月。
右侧:“一只狗在追逐一个红色的球。”
与其他AI视频生成器的比较
以下示例是与两个最受欢迎的AI视频生成器Pika 1.0和Runway Gen2的比较。
注意:Pika和Gen-2使用图像和文本条件;Boximator使用从文本提示中得出的额外框约束。
提示:“往杯子里倒酒。” “一个英俊的男人正用右手从口袋里拿出一朵玫瑰,凝视着这朵玫瑰。”
“一个英俊的男人正用右手从口袋里拿出一朵玫瑰,凝视着这朵玫瑰。” 提示:“两只穿着蓝衬衫的浣熊正在玩球,左边的浣熊正在跳起来。”
提示:“两只穿着蓝衬衫的浣熊正在玩球,左边的浣熊正在跳起来。” 你对这些视频怎么看?
你对这些视频怎么看?
通过查看这些示例,可以明显看出,添加额外的控制层会增强结果。Boximator生成的视频比Pika和Gen2生成的更具动态感。
如何尝试
演示网站目前对公众不可用。根据其创造者的说法,它应该在接下来的几个月内提供。
我们的演示网站正在开发中,预计将在接下来的2-3个月内上线。一旦演示准备就绪,我们将在此网站上附上演示链接。
如果你真的想尝试Boximator,可以通过电子邮件联系创造者,邮箱是 wangjiawei.424@bytedance.com,发送输入图像和文本提示,他们会回复生成的视频。
最后思考
作为一个科技爱好者,我感到很兴奋,看到科技巨头们展示像Boximator和Sora这样的软件,这些技术在不久的将来可能会触手可及。
然而,重要的是要意识到与这项技术相关的风险。与任何强大的工具一样,存在滥用的潜力。例如,深度伪造可能会被用来传播虚假信息或宣传。
赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052