

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
如何使用 AI 写出超过 10,000 字的论文、报告或书籍
5 个月前
如何使用 AI 写出 10,000+ 字的论文、报告或书籍
对于生成长篇内容的需求是真实存在的——无论是 10,000+ 字的论文、详细的报告,还是一本书。
大家都在尝试使用 GPT-4o 或 Claude 3.5 Sonnet 等各种方法,但效果都不尽如人意。
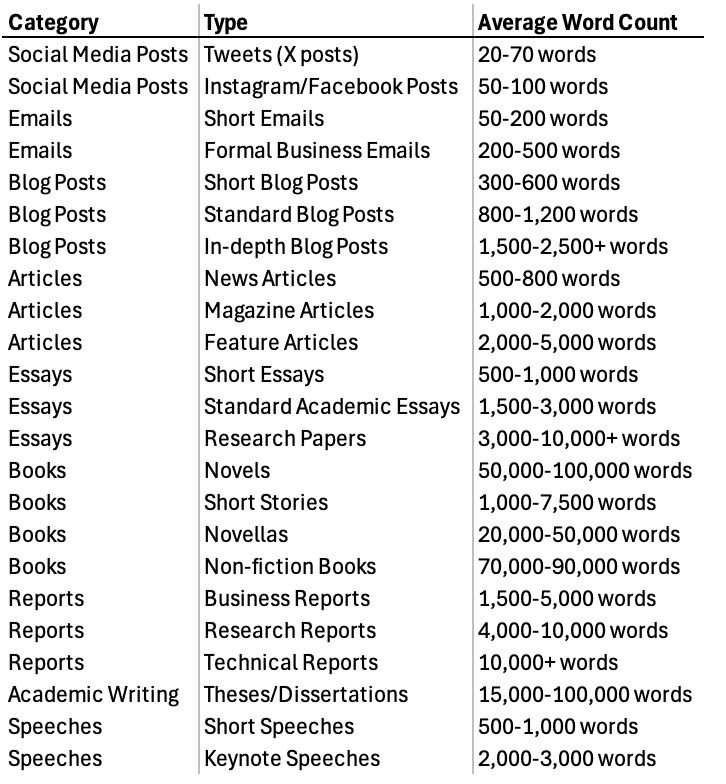
以下是不同类型文本的平均字数:
如今,超长上下文的大型语言模型(LLMs)可以一次处理超过 100,000 个标记,但我们知道它们在生成同样长的响应时却很挣扎。
虽然它们可以接受这么长的上下文,但一次生成的字数通常不超过 2,000 字。
我们如何突破这些限制?似乎终于看到了隧道尽头的光明。
如何测试 10,000 字挑战的极限?
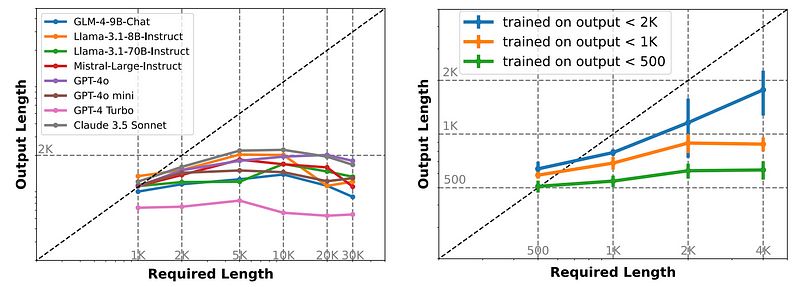
清华大学和智谱 AI 的研究人员尝试用“写一篇关于罗马帝国历史的 10,000 字文章”这样的提示来推动大型模型——结果如何?
每个模型都未能达到目标,最多只能生成约 2,000 字。这就像让一个马拉松选手去跑超马,但他们在第 20 英里时就撞墙了。
真是令人沮丧……
有趣的是,这并不是一个偶然的失误。
当团队深入分析 WildChat 的用户交互日志时,发现超过 1% 的用户提示明确要求生成超过 2,000 字的输出。
这是一大群等待服务的客户!
为什么大型语言模型会遇到瓶颈?
那么,问题出在哪里呢?
团队越深入研究,越清楚问题并不在于模型的架构本身,而在于它所训练的数据——特别是监督微调(SFT)数据集。
这些数据集是模型生成输出所依赖的,似乎在长度上有一个上限。
这些数据集的最大输出长度?没错,约 2,000 字。
这就像是想成为小说家,但你读的全是短篇故事。
这解释了为什么模型会遇到瓶颈。
搭建梯子:引入 AgentWrite
但你知道人们常说的——当你撞墙时,是时候搭建梯子了。
这就是 AgentWrite 的用武之地。
这是一个基于代理的管道,研究团队一直在努力开发,巧妙地利用现有的 LLMs 来生成更长、更连贯的输出。
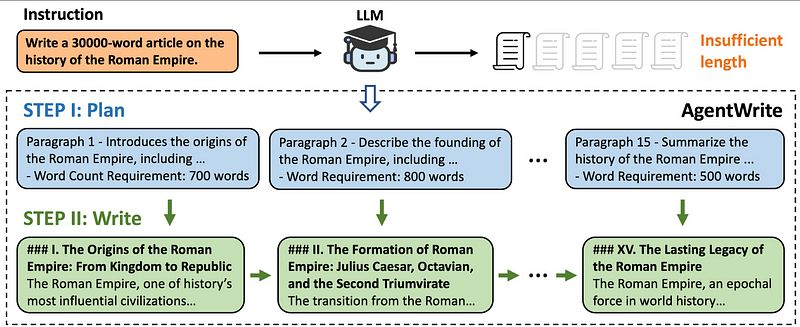
它的工作原理如下:
- 首先,它创建一个详细的计划,类似于大纲,绘制出每个段落的结构和目标字数。
- 然后,它将这个计划输入模型,逐步提示生成内容。
- 结果是高质量、连贯的文本,字数可达 20,000 字。
不错吧?
通过 LongWriter-6k 数据集扩展能力
但团队并没有止步于此。
在 AgentWrite 管道的基础上,他们更进一步,创建了 LongWriter-6k——一个旨在锻炼模型写作能力的数据集。
通过在 LongWriter-6k 上进行训练,他们成功解锁了模型生成超过 10,000 字的潜力。
他们还开发了 LongBench-Write,这是一个包含多样化写作任务的基准,从短小片段到史诗般的内容,严格测试模型的能力。
在长篇内容生成方面开辟新天地
结果如何?
他们的 9B 模型在长篇内容生成方面现在超越了甚至更大的专有模型。得益于 DPO(直接偏好优化)方法,模型不仅生成的内容更长——而且质量更高。
总结一下,研究团队取得了以下成就:
- 破解长度密码: 他们找到了这些长上下文模型在约 2,000 字时卡住的真正原因——训练数据的限制。
- 构建新工具: AgentWrite,他们的分而治之的方法,帮助模型生成超长输出,同时保持连贯性和质量。
- 突破边界: 通过 LongWriter-6k 数据集,他们将模型的输出能力扩展到超过 10,000 字,而不牺牲质量。
让我们看看它在实践中的表现吧!
在这里恳请您:
我们为希望构建受人喜爱的 AI 产品的独立创业者发布“如何做”指南!
我们倾注了热情、专业知识和无数小时的努力来创建内容,相信这些内容能在您的旅程中产生积极影响。
只是我们只有 1% 的读者在 Medium 上与我们互动或关注,这让我们非常……非常难过。
如果您在这里学到的内容对您有价值,请花一点时间 关注我们在 Medium 上,为这篇文章点赞并留言——这虽然是一个小小的举动,但对我们意义重大,帮助我们提供更好的内容和指南!
使用 LongWriter LLMs 写作 10,000+ 字的文章和书籍
团队开源了两个模型:
这些模型分别基于 GLM-4–9B 和 Meta-Llama-3.1–8B 进行训练。
这两个模型在他们的 论文 中也指向了“LongWriter-9B-DPO”和“LongWriter-8B”模型。
团队建议使用 transformers==4.43.0 来成功部署我们的模型。对于 LongWriter-glm4-9b 模型,请确保根据 FlashAttention 的代码库安装 FlashAttention 2。
以下是您如何尝试该模型的方法:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("THUDM/LongWriter-glm4-9b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("THUDM/LongWriter-glm4-9b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
model = model.eval()
query = "写一篇 10000 字的中国旅行指南"
response, history = model.chat(tokenizer, query, history=[], max_new_tokens=32768, temperature=0.5)
print(response)
就是这么简单!
您还可以通过运行以下命令来部署自己的 LongWriter 聊天机器人:
CUDA_VISIBLE_DEVICES=0 python trans_web_demo.py
如果您在生成长篇内容时遇到困难,请在评论中告诉我们!
进一步了解 LongWriter 的资源
赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052