

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
NVIDIA的Wolf:世界总结框架在视频标题生成方面比GPT-4V高出55.6%
5 个月前
NVIDIA的Wolf:世界摘要框架在视频字幕生成上超越GPT-4V,提升55.6%

视频字幕生成对于提高内容的可访问性和可搜索性至关重要,因为它提供了精确且可搜索的视频内容描述。然而,由于高质量标注数据的有限性以及视频字幕生成中涉及的额外复杂性(如时间相关性和摄像机运动),生成准确、描述性强且详细的视频字幕仍然是一项挑战。
为应对这些挑战,在一篇新论文《Wolf: 用世界摘要框架生成字幕》中,来自NVIDIA、加州大学伯克利分校、麻省理工学院、德克萨斯大学奥斯汀分校、多伦多大学和斯坦福大学的合作研究团队开发了一种新方法,称为WOrLd摘要框架(Wolf)。该自动字幕生成框架显著提升了视频字幕生成的效果,相比于GPT-4V,CapScore的质量提高了55.6%,相似性提高了77.4%。

研究团队强调了他们工作的三个关键贡献:
- 引入Wolf: 他们开发了第一个用于视频字幕生成的世界摘要框架,并提出了一种新的基于LLM的指标CapScore,用于评估字幕质量。他们的方法在CapScore上显示出显著的提升。
- 创建Wolf基准: 团队引入了Wolf基准,包括四个人工标注的数据集,涵盖自动驾驶、Pexels的普通场景和机器人视频。这些数据集以及人工标注的字幕构成了Wolf数据集。
- 开源倡议: 与Wolf相关的代码、数据和排行榜将开源,并在Wolf网页上维护,持续努力提升Wolf数据集、代码库和CapScore。
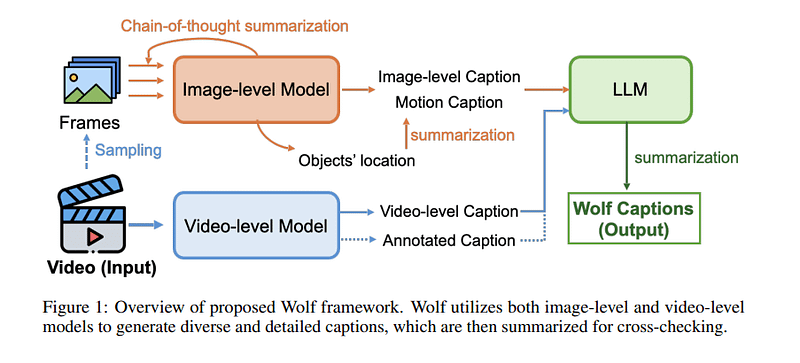
Wolf采用了一种复杂的方法,结合专家模型生成全面且精确的视频字幕。该框架利用图像级和视频级模型生成多样且详细的字幕,然后通过摘要进行交叉验证。具体而言,Wolf使用CogAgent和GPT-4V生成图像级字幕,使用VILA-1.5和Gemini-Pro-1.5生成视频级字幕。
图像级模型中的思维链摘要。由于基于图像的视觉语言模型(VLM)在比基于视频的VLM上训练了更大规模的数据集,因此该过程首先使用基于图像的VLM生成字幕。视频被分割成连续的图像,每秒采样两个关键帧。图像1由图像级模型处理,生成字幕1,其中包含详细的场景信息和物体位置。考虑到帧之间的时间关系,字幕1和图像2一起用于生成字幕2。这个过程持续进行,直到为所有关键帧生成字幕。然后,这些字幕的信息通过GPT-4进行摘要,使用的提示旨在确保视频描述中的时间表示准确。
基于LLM的视频摘要。在生成图像级字幕后,这些字幕被总结为一个连贯的字幕。这个过程涉及总结图像和视频模型描述中的视觉和叙事元素的提示,特别关注运动行为。
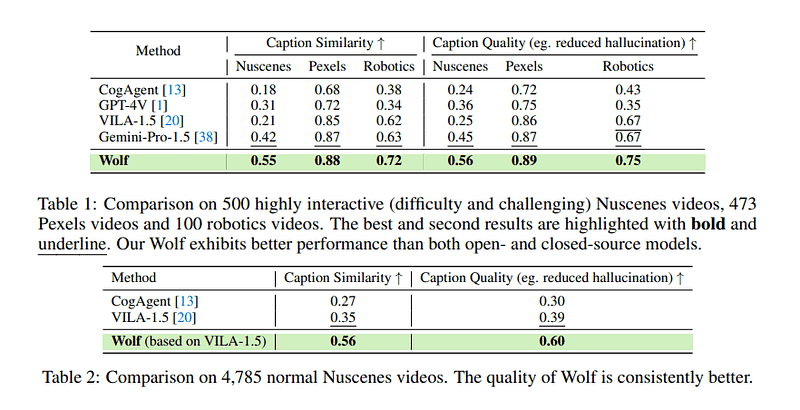
实证结果表明,Wolf在现有的最先进解决方案中表现优异,包括研究工具(VILA-1.5、CogAgent)和商业工具(Gemini-Pro-1.5、GPT-4V)。研究团队希望Wolf能在视频字幕质量上树立新的标杆,提高该领域的关注度,并促进社区内的进一步发展。
代码可在项目的网页上获取。论文《Wolf: 用世界摘要框架生成字幕》可在arXiv上找到。
作者:Hecate He | 编辑:Chain Zhang

赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052