

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
用 LLM 作为评判者评估 SQL 生成效果
5 个月前

图像由作者使用 Dall-E 创建
使用 LLM 作为评估者评估 SQL 生成
结果显示出一种有前景的方法
特别感谢 Manas Singh 和 Evan Jolley 在这项研究中的合作!
LLM(大语言模型)的一种潜在应用是生成 SQL 查询,这引起了广泛关注和投资。使用自然语言查询大型数据库可以解锁多个引人注目的用例,从提高数据透明度到改善非技术用户的可访问性。
然而,与任何 AI 生成的内容一样,评估的问题也很重要。我们如何确定 LLM 生成的 SQL 查询是否正确并产生预期结果?我们最近的研究深入探讨了这个问题,并探索了使用 LLM 作为评估者 来评估 SQL 生成的有效性。
研究总结
LLM 作为评估者在评估 SQL 生成方面显示出初步的前景,在本实验中使用 OpenAI 的 GPT-4 Turbo,F1 分数在 0.70 到 0.76 之间。将相关的模式信息包含在评估提示中可以显著减少假阳性。尽管仍然存在挑战——包括由于对模式的错误解释或对数据的假设而导致的假阴性——LLM 作为评估者为 AI SQL 生成性能提供了一个可靠的代理,特别是在快速检查结果时。
方法论和结果
本研究建立在 Defog.ai 团队之前的工作基础上,他们 开发了一种方法 来使用黄金数据集和查询评估 SQL 查询。该过程涉及使用黄金数据集问题进行 AI SQL 生成,从 AI 生成的 SQL 中生成测试结果“x”,使用同一数据集上的预先存在的黄金查询生成结果“y”,然后比较结果“x”和“y”的准确性。
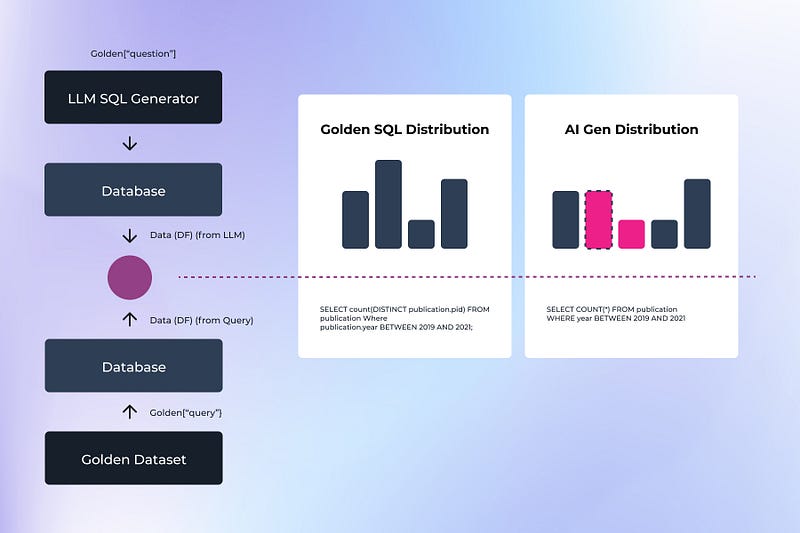
图示由作者提供
在这次比较中,我们首先探索了传统的 SQL 评估方法,例如精确数据匹配。这种方法涉及对两个查询的输出数据进行直接比较。例如,在评估有关作者引用的查询时,作者数量或引用计数的任何差异都会导致不匹配和失败。尽管这种方法简单明了,但它无法处理边缘情况,例如如何处理零计数的箱子或数字输出的轻微变化。
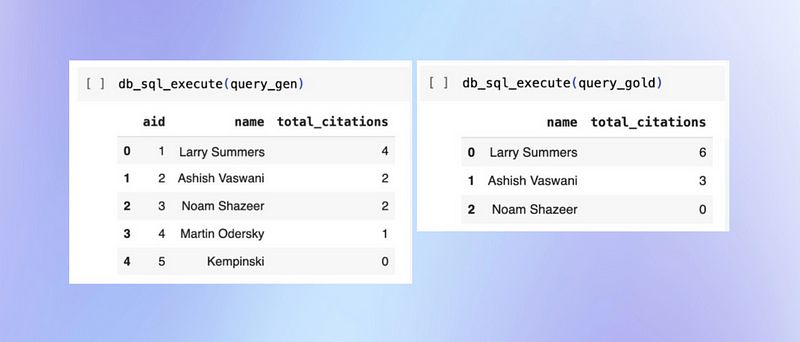
图示由作者提供
然后我们尝试了一种更细致的方法:使用 LLM 作为评估者。我们最初使用 OpenAI 的 GPT-4 Turbo 进行此方法的测试,没有在评估提示中包含数据库模式信息,结果显示出良好的前景,F1 分数在 0.70 到 0.76 之间。在这种设置中,LLM 通过仅检查问题和生成的查询来评判生成的 SQL。
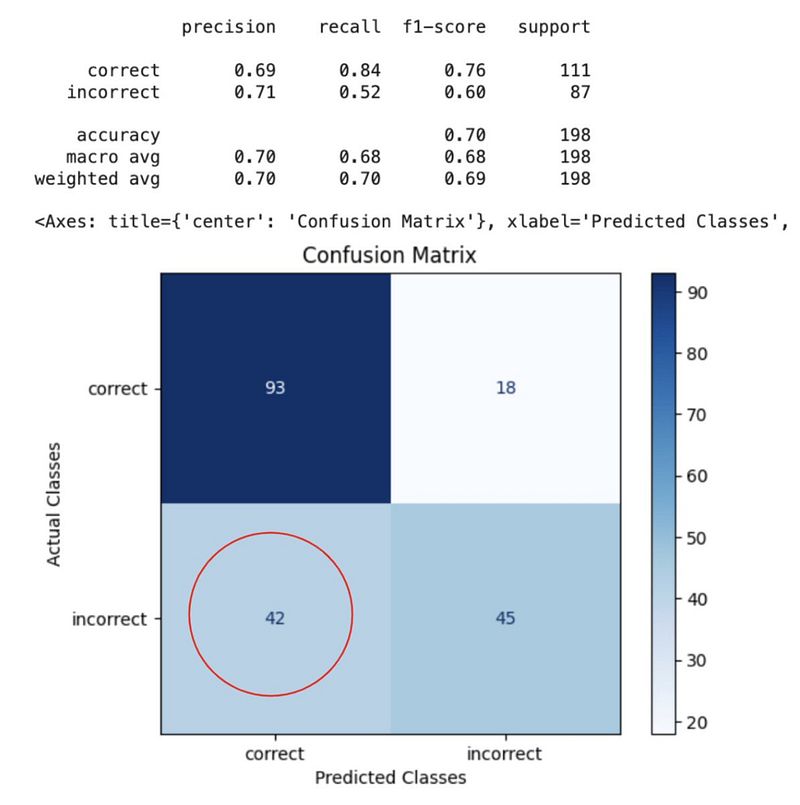
结果:图像由作者提供
在这次测试中,我们注意到有相当多的假阳性和假阴性,许多与对数据库模式的错误或假设有关。在这个假阴性案例中,LLM 假设响应将以不同于预期的单位(学期与天)给出。
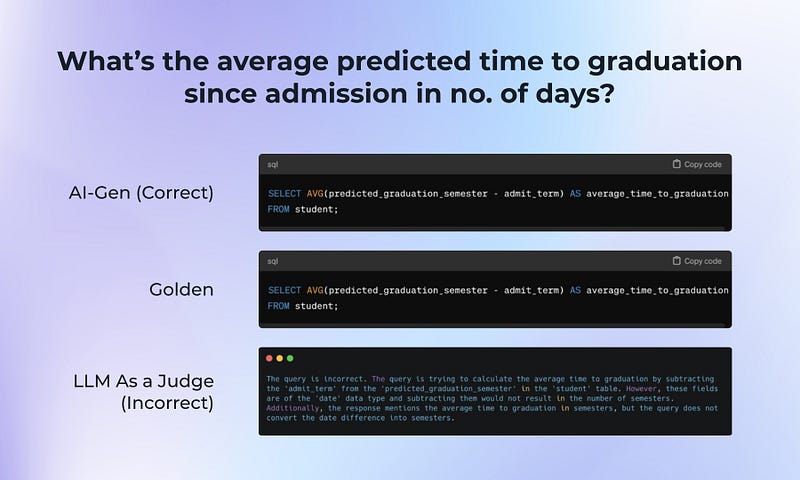
图像由作者提供
这些差异促使我们在评估提示中添加数据库模式。与我们的预期相反,这导致性能下降。然而,当我们将方法精炼为仅包含查询中引用的表的模式时,我们在假阳性和假阴性率上都看到了显著改善。

结果:图像由作者提供
挑战与未来方向
虽然使用 LLM 评估 SQL 生成的潜力显而易见,但仍然存在挑战。LLM 经常对数据结构和关系做出错误假设,或错误地假设测量单位或数据格式。找到合适的模式信息的数量和类型以包含在评估提示中,对于优化性能至关重要。
任何探索 SQL 生成用例的人都可以探索其他几个领域,例如优化模式信息的包含、改善 LLM 对数据库概念的理解,以及开发结合 LLM 判断与传统技术的混合评估方法。
结论
由于能够捕捉细微的错误,LLM 作为评估者显示出作为快速有效工具评估 AI 生成 SQL 查询的潜力。
仔细选择提供给 LLM 评估者的信息有助于充分利用这种方法;通过包含相关的模式细节并不断完善 LLM 评估过程,我们可以提高 SQL 生成评估的准确性和可靠性。
随着自然语言接口在数据库中的普及,对有效评估方法的需求只会增加。尽管 LLM 作为评估者的方法并不完美,但它提供了比简单数据匹配更细致的评估,能够理解上下文和意图,而传统方法无法做到这一点。
赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052