

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
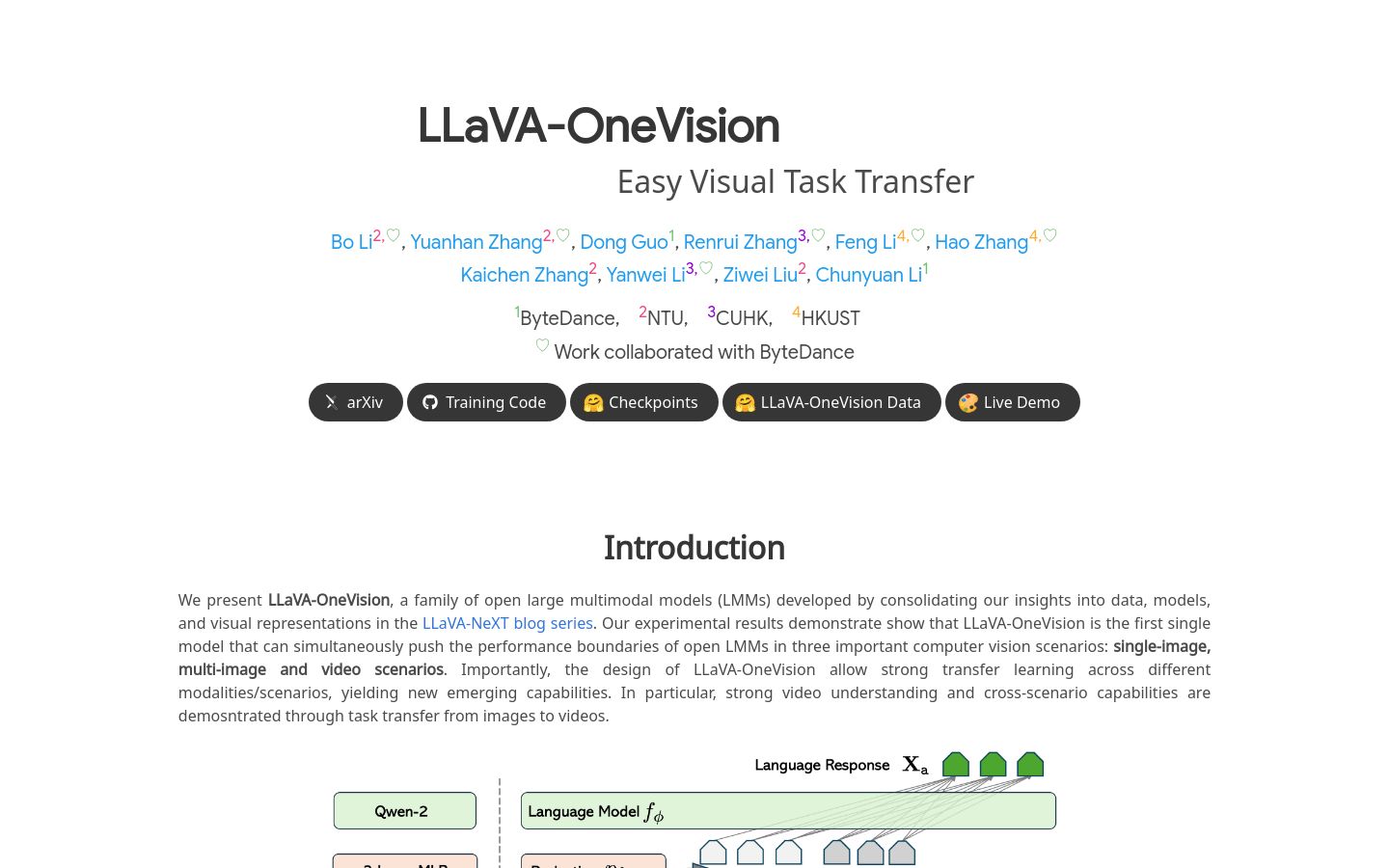
LLaVA-OneVision
8 个月前
多模态视觉识别人工智能图像处理视频分析
LLaVA-OneVision是一款由字节跳动公司与多所大学合作开发的多模态大型模型(LMMs),它在单图像、多图像和视频场景中推动了开放大型多模态模型的性能边界。该模型的设计允许在不同模态/场景之间进行强大的迁移学习,展现出新的综合能力,特别是在视频理解和跨场景能力方面,通过图像到视频的任务转换进行了演示。


赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052