

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
BERT——直观而详尽的解读
5 个月前
在这篇文章中,我们将讨论“来自变换器的双向编码器表示” (BERT),这是一个旨在理解语言的模型。虽然BERT与GPT等模型相似,但BERT的重点在于理解文本而不是生成文本。这在许多任务中非常有用,比如评估产品评论的积极程度,或预测某个问题的答案是否正确。
在深入讨论BERT之前,我们将简要介绍变换器架构,这是BERT的直接灵感来源。通过理解这一点,我们将深入探讨BERT,讨论它是如何构建和训练的,以利用对语言的普遍理解来解决问题。最后,我们将从头开始创建一个BERT模型,并用它来预测产品评论是积极的还是消极的。
这对谁有用? 任何想要全面了解人工智能前沿技术的人。
这篇文章的难度如何? 文章的早期部分适合各个水平的读者,而后面的从零开始实现部分则相对较为高级。必要时会提供补充资源。
前提条件: 我强烈建议在阅读实现部分之前,先了解PyTorch的基本概念。你可以在这里了解更多关于PyTorch的信息:
绝对新手的人工智能 — 直观且详尽的解释 从“我从未编码”到从零开始制作AI模型。towardsdatascience.com
了解变换器和多头自注意力机制可能对后面的部分有帮助,但并不是必需的。
变换器概述
到目前为止,我已经详细介绍了变换器及其衍生架构。
变换器 — 直观且详尽的解释 探索现代机器学习的浪潮:逐步拆解变换器。towardsdatascience.com
多头自注意力 — 手动计算 现代人工智能的基石。towardsdatascience.com
GPT — 直观且详尽的解释 探索OpenAI的生成预训练变换器的架构。towardsdatascience.com
Flamingo — 直观且详尽的解释 现代视觉语言建模背后的架构。towardsdatascience.com
让我们回顾一下要点。
从最基本的角度来看,变换器是一个“编码器/解码器”风格的模型。当你将某些内容输入变换器时,编码器将输入总结为某种富有意义和抽象的表示,解码器则利用该表示生成输出。
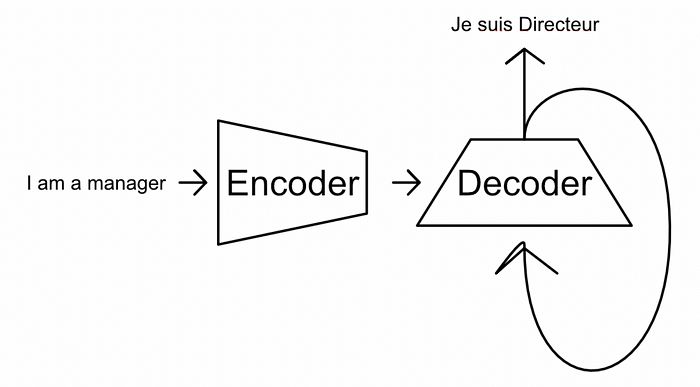
编码器-解码器模型的核心思想。编码器将输入转换为某种抽象表示,解码器则用于生成输出。在这个特定的例子中,编码器和解码器共同工作,将英语短语翻译成法语。来自我关于变换器的文章。
变换器使用多种人工智能构建模块来完成这一通用过程,如其架构图所示。
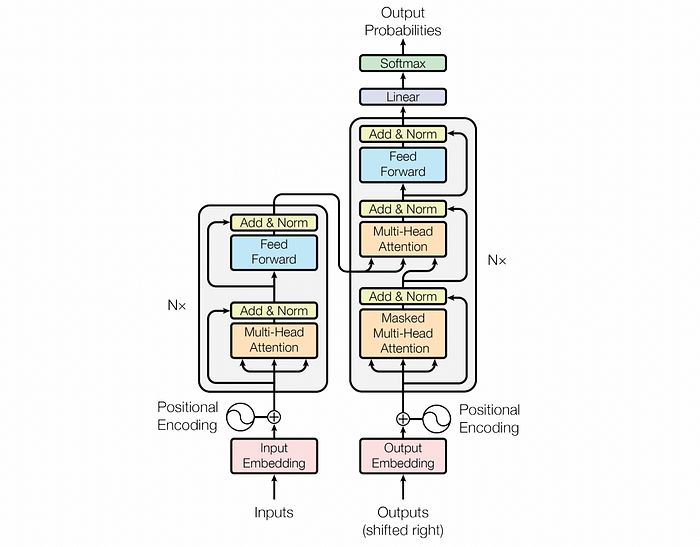
变换器图。 来源
首先,输入嵌入将单词转换为向量。这将难以进行数学运算的单词转换为更易于进行数学运算的数字。
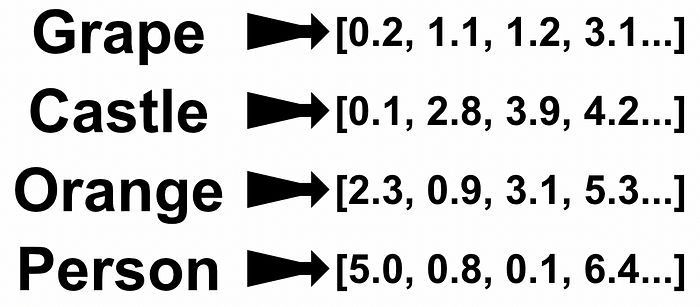
单词到向量的嵌入。来自我关于变换器的文章。
然后,我们为每个输入位置创建对应的向量,并将这些位置向量添加到单词向量中。因此,每个结果向量都包含有关单词及其位置的信息。
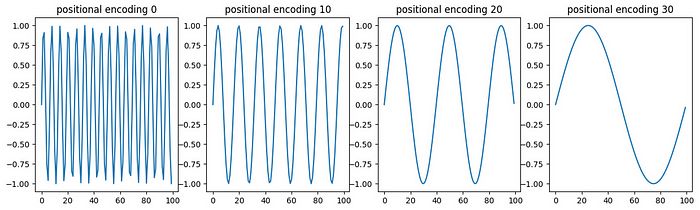
根据位置的不同,添加不同值的向量到单词向量中。来自我关于变换器的文章。
对输入短语应用一种称为多头自注意力的过程。这种相对复杂的操作在很大程度上是变换器的定义特征。我们稍后会详细讨论这一点,但现在我们只需说,多头自注意力机制使输入序列中的每个单词与输入序列中的每个其他单词相互作用。输出是输入的抽象和富有意义的表示。

多头自注意力允许输入与自身相互作用,创建一个复杂的矩阵,表示整个输入。来自我关于变换器的文章。
多头自注意力机制是一种复杂的操作。为了使模型训练更容易,某些较旧且较简单的输入结构被添加到注意力机制的输出中,以保留一些简单的表示。这被称为跳跃连接。

跳跃连接的概念图。来自我关于变换器的文章。
然后,通过一种称为“归一化”的过程,将可能分散的值压缩到合理的分布中。在注意力机制之后,数据会通过神经网络进行处理。
整个过程的结果是一个形状与输入相似但更复杂和抽象的输出。
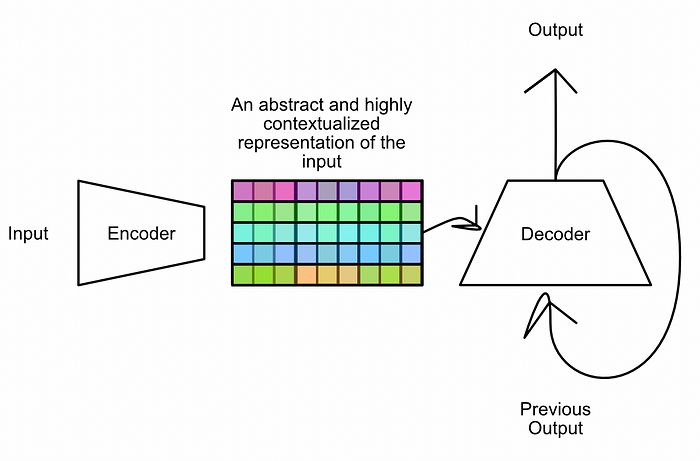
编码器的任务是为解码器最佳表示输入。解码器的任务是生成输出。来自我关于变换器的文章。
“解码器”本质上由与编码器相同的核心组件构成,但其目标不同。编码器将输入上下文化为编码,而解码器则利用编码构建输出。
这就是变换器的基本概念。我们略过了很多内容,如果你想了解更多,可以查看一些链接。不过现在,我们可以开始深入探讨BERT的核心思想。
编码器与解码器风格模型
最初的变换器像烟花一样点燃了人工智能。从作为英语到法语翻译模型的谦卑起步,它已经扩展成为一个价值数百亿美元的行业的基石。当变换器被发明时,它继承了当时许多流行的机器学习概念,特别是将语言建模视为“序列到向量再到序列”的任务。
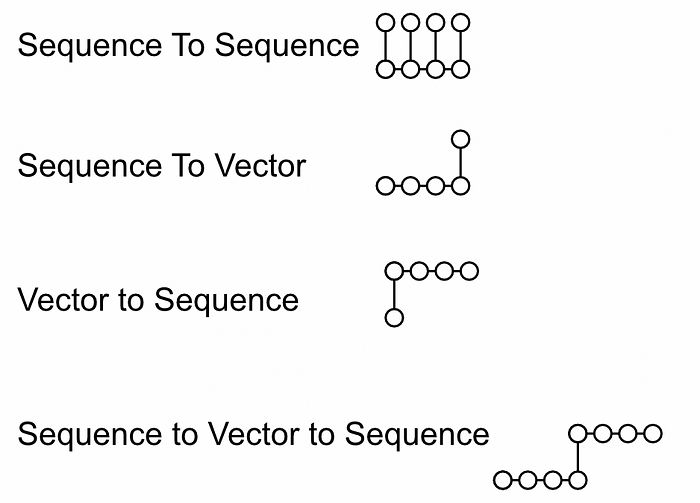
不同类型序列建模的几个应用的概念图。序列到序列可能是预测文本完成的下一个单词。序列到向量可能是评估客户对评论的满意度。向量到序列可能是将图像压缩为向量,并要求模型将该图像描述为文本序列。序列到向量再到序列可能是文本翻译,其中需要理解一个句子,将其压缩为某种表示,然后在另一种语言中构建该压缩表示的翻译。来自我关于变换器的文章。
这在递归神经网络中是一个流行的概念,而递归神经网络是变换器之前流行的建模架构。变换器是这一思想的衍生物,因此被构建为“序列到向量再到序列”建模的变体,这正是编码器和解码器的本质。
在变换器爆炸性流行之后,出现了一个新的研究时代(并且仍在持续),鼓励围绕变换器架构进行广泛的实验。这个研究中出现的一个强大思想是“仅编码器”和“仅解码器”风格模型的概念。
GPT就是一个“仅解码器”风格模型。基本上,解码器仅是变换器的右半部分。GPT将输入输入到解码器中,然后使用该解码器生成输出,而不是将输入输入到编码器中。

GPT的概念图,一个仅解码器模型,生成输出。来自我关于GPT的文章。
这种更简单的架构具有一些关键优势,特别是在训练方面,使模型能够更轻松地从大量文本数据中学习。
虽然仅解码器模型已经爆炸性流行,但“仅编码器”模型在构建先进的人工智能系统中也是另一个重要工具。请记住,编码器和解码器几乎是相同的,唯一的区别在于它们的工作;编码器将输入总结为抽象且富有意义的表示,而解码器则生成文本。
因此,“仅编码器”变换器的目的是将某些输入序列总结为抽象、密集且富有意义的表示。与专门为文本生成创建该表示不同,“仅编码器”变换器的目的是创建一个在多种任务中普遍有用的表示。
BERT是最著名的仅编码器模型,在需要一定语言理解的任务中表现出色。
BERT — 来自变换器的双向编码器表示
在变换器之前,如果你想预测一个答案是否回答了一个问题,你可能会使用像LSTM这样的递归策略。
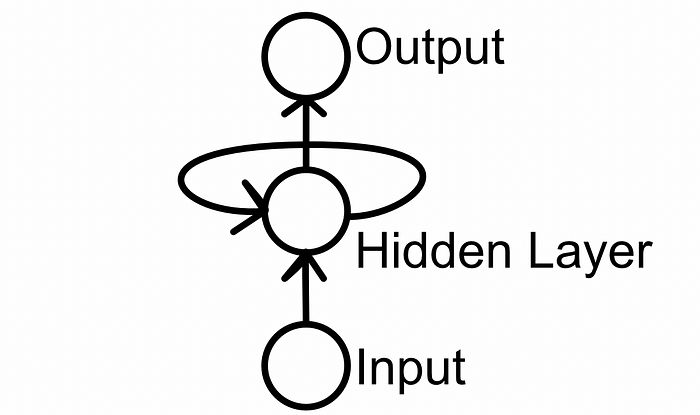
递归模型的一般概念,这是一种在连续输入中自我反馈的模型。来自我关于变换器的文章。
这种方法的一个问题是信息局部性。LSTM按顺序传递信息,以创建一个表示模型预测的向量。因此,序列中更远的信息更难以相互作用。这有点像你小时候玩过的电话游戏。序列越长,模型就越容易忘记重要但遥远的信息,因为这些信息被迫通过连续输入与其他信息相互作用。
人工智能研究人员做了各种尝试来缓解信息局部性的问题。他们使用了相反方向的递归网络,试图将“双向”理解融入模型,使模型能够向前和向后查看。
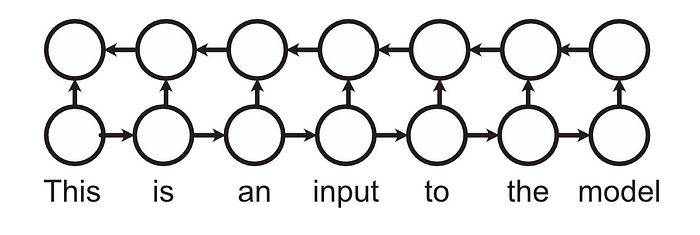
双向递归网络的概念图:从左到右和从右到左的网络。
还有一些策略,比如层次递归网络,试图利用前一层的总结来保留更多的长距离信息。
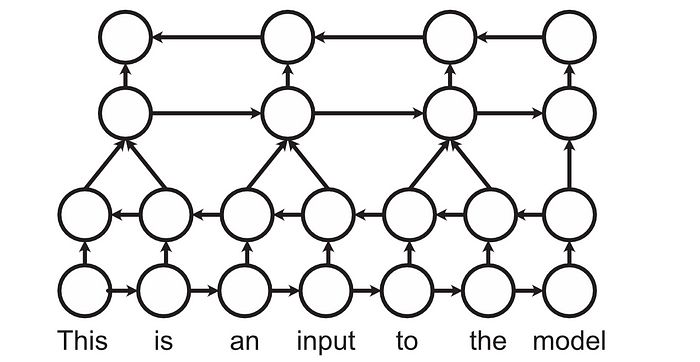
同时双向和层次递归网络的概念图。
虽然这些策略在一定程度上解决了问题,但它们并没有根本解决。最终,递归网络是空间依赖的。
变换器的一个酷炫之处在于它们能够处理大输入序列中的信息。如果序列中的两个单词彼此相关,变换器可以将这两个单词一起操作,而不管它们相距多远。这要归功于自注意力机制。
自注意力机制分析输入,然后构建一个矩阵,表示输入中哪些单词与哪些其他单词相关。然后,它使用该矩阵使表示这些单词的向量相互作用。

自注意力允许任何输入任意地与任何其他输入相互作用。通常,输入最常与自身和附近的标记相互作用,但这并不一定是这样。
这就是BERT名称中包含“双向”一词的原因。虽然递归网络可以通过结合从右到左和从左到右的分析来实现一种弱形式的双向性,但变换器能够实现任意的双向性。实际上,我认为称BERT风格的变换器为“全向”可能更好,但“OERT”这个词并不容易说出口。
这种思维方式的转变帮助BERT一夜之间取得了成功。在发布后,它在几个之前被递归策略主导的成熟基准上表现出色。这种性能的提升可能归因于BERT能够让输入序列中的元素任意相互作用,而不是强烈偏向空间接近性。
它如此成功的另一个原因是它的训练方式,我们将在下一部分中讨论。
训练BERT模型
BERT风格的模型采用了两种训练方法,称为“预训练”和“微调”。
摘自 我关于LoRA的文章 _,一种微调方法。
随着机器学习的前沿技术不断发展,对模型性能的期望也在提高;这需要更复杂的机器学习方法来满足对更高性能的需求。在机器学习的早期阶段,构建一个模型并在一次性传递中训练它是可行的。
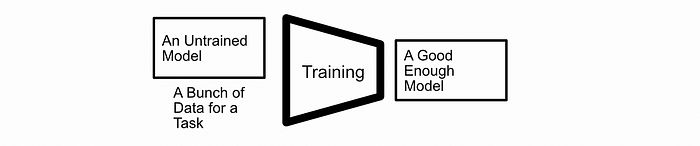
训练,最简单的说法是。你拿一个未训练的模型,给它数据,然后得到一个性能良好的模型。
这仍然是解决简单问题的流行策略,但对于更复杂的问题,考虑将训练视为两个部分:“预训练”然后“微调”可能会更有用。一般的想法是在一个大数据集上进行初步训练,然后在一个定制的数据集上对模型进行细化。
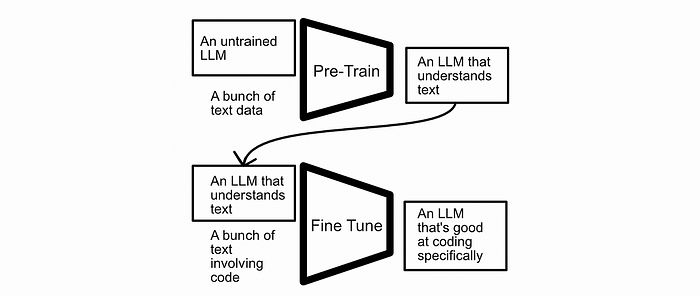
预训练和微调,典型训练策略的细化。
这种“预训练”然后“微调”的策略可以让数据科学家利用多种数据形式,并使用大型预训练模型来处理特定任务。因此,预训练然后微调是一种常见且极其强大的范式。
BERT使用的预训练步骤旨在鼓励模型普遍理解语言,然后允许微调以使模型学习特定任务。首先,让我们讨论预训练。
BERT预训练
BERT同时在两个目标上进行预训练:“掩码语言建模”,类似于填空,以及“下一个句子预测”,本质上是要求模型预测两个句子是否相互关联。
对于下一个句子预测,假设我们有一些文本,可以将其分解为句子列表。
['我很伤心。',
'我吃了一个百吉饼,但我仍然很饿。',
'我不喜欢饿肚子。',
'但是,我知道我很快就会再吃!',
'我想我会去Fudruckers。'
'不过,我不确定Fudruckers是否有百吉饼。'
]
首先,我们可以取两个句子,其中我们知道第二个句子跟随第一个句子,然后将它们组合在一起。
('我很伤心。', '我吃了一个百吉饼,但我仍然很饿。')
我们还可以组合两个不相互跟随的句子。
('我很伤心。', '我不确定Fudruckers是否有百吉饼。')
然后,我们可以构建一个句子数据集,其中包含相互跟随和不相互跟随的句子。这将通过一个包含许多句子的庞大语料库来完成。
相互跟随 | 句子
------------------
真 | ('我很伤心。', '我吃了一个百吉饼,但我仍然很饿。')
假 | ('我很伤心。', '我不确定Fudruckers是否有百吉饼。')
...
因此,我们已经为下一个句子预测创建了一个数据集。如果我们将一个人工智能模型应用于这个任务,它将必须在足够的程度上理解语言,以理解哪些句子是相互关联的,哪些不是。
我们还可以通过随机替换数据集中的单词来添加掩码语言建模。
相互跟随 | 句子
------------------
真 | ('我[MASK]伤心。', '我吃了一个百吉饼,但我仍然很饿。')
假 | ('我很伤心。', '我不确定Fudruckers[MASK]百吉饼。')
...
因此,对于给定的输入,模型在预训练期间将有两个任务:
- 预测第二个句子是否跟随第一个句子。
- 预测掩码单词应该是什么。
这个想法是,如果你用大量文本进行这个操作,模型就会被迫对语言有一个扎实的普遍理解。它可以理解句子,以足够的程度理解句子在配对时是否有意义,并可以利用上下文线索来理解掩码部分应该存在哪些单词。
为了进行这些预测,BERT在传统的编码器风格变换器模型上添加了一些东西。首先,BERT有几个特殊的标记,称为“实用标记”,它们被放置在序列中,以便在输入中表示这两个句子。首先,它在序列的开头添加一个标记[CLS],稍后将用于分类该序列是否是一个积极的下一个句子对。然后,标记[SEP]被添加到输入中,以将两个句子彼此分开。标记[MASK]也存在,如前所述。
'[CLS] 我[MASK]伤心。[SEP] 我吃了一个百吉饼,但我仍然很饿。'
这些标记以文本形式表示,以便于理解,但实际上它们是数字。输入被分解为一个数字列表,其中每个数字表示序列中的一个单词或实用标记。
# 概念演示,将输入标记化为数字列表。
[CLS] = 101
我 = 1023
[MASK]= 103
伤心 = 39842
[SEP] = 102
我 = 1023
吃 = 8907
一个 = 213
百吉饼 = 208756
但 = 9867
我 = 2367
仍然 = 7893
很饿 = 55678
(实际上,标记化是通过子词进行的,但我们将在实现中讨论这一点。)
因此,在预训练中,我们给BERT风格模型这些标记,并要求它预测两件事:句子是否相关,以及掩码位置应该是什么。然后,我们根据模型的错误程度更新模型。
BERT微调
BERT的预训练过程的一个酷炫之处在于,你可以向模型暴露大量文本,从而使模型形成非常强大的语言理解。微调步骤利用这种理解并将其应用于特定问题。
微调的确切过程取决于你试图微调的数据类型。让我们以情感分析为例。
假设我们有以下产品评论数据集,其中包含评论的标题、评论的正文,以及评论是积极的还是消极的标签。
积极 | 标题 | 正文
------------------------------------------------------------------------
真 | 令人惊叹 | 我终于找到了有效的东西!
假 | 不好 | 第一次使用后就坏了
...
这个数据集可以被处理成与我们原始数据集相似的格式(你可以根据微调的数据集选择不同的重新表示模式)。
积极 | 序列
------------------------------------------------------------------------
真 | [CLS] 令人惊叹 [SEP] 我终于找到了有效的东西!
假 | [CLS] 不好 [SEP] 第一次使用后就坏了
...
然后,我们可以再次训练我们的模型,就像在预训练中那样,但在这个新的、更具体的数据集上。通过训练,模型将学习将其对下一个句子预测的理解转化为对序列是积极还是消极评论的理解。
通常,在不同目标上进行微调时,最好替换“预测头”。我在这里讨论了这个主题的文章。
使用投影头的自监督学习 利用未标记数据提升性能。towardsdatascience.com
在BERT风格模型中,使用一个密集网络将与[CLS]标记对应的输出转换为句子是否相关的真或假预测。替换投影头的想法是用一个随机初始化的组件替换该学习组件。这样,模型就不需要学习去预测下一个句子,而是可以直接用一个新的、随机初始化的神经网络替换分类的神经网络。这通常使模型更容易转向学习新领域。
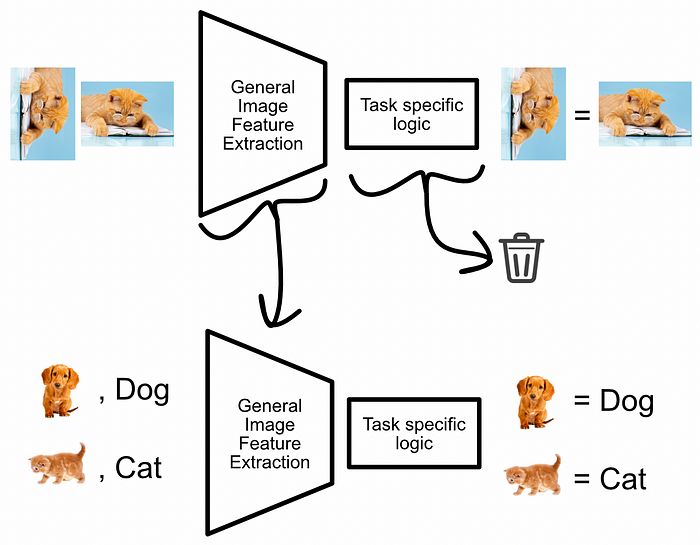
投影头的概念图。虽然这是一个图像分类任务,但理论是相似的。来自我关于投影头的文章。
如果你不完全理解投影头,不用担心,我们将在实现中详细讨论。让我们更仔细地探索BERT的输入和输出,然后开始编码。
BERT的输入
回想一下,我们使用标记化将单词转换为数字。
# 概念演示,将输入标记化为数字列表。
[CLS] = 101
我 = 1023
[MASK]= 103
伤心 = 39842
[SEP] = 102
我 = 1023
吃 = 8907
一个 = 213
百吉饼 = 208756
但 = 9867
我 = 2367
仍然 = 7893
很饿 = 55678
每个数字随后通过一种称为“嵌入”的过程转换为向量。基本上,我们为每个可能的标记创建一大组随机向量,然后在序列中使用该标记时使用相应的向量。这些大查找表的向量值是随机初始化的,并在训练过程中更新。
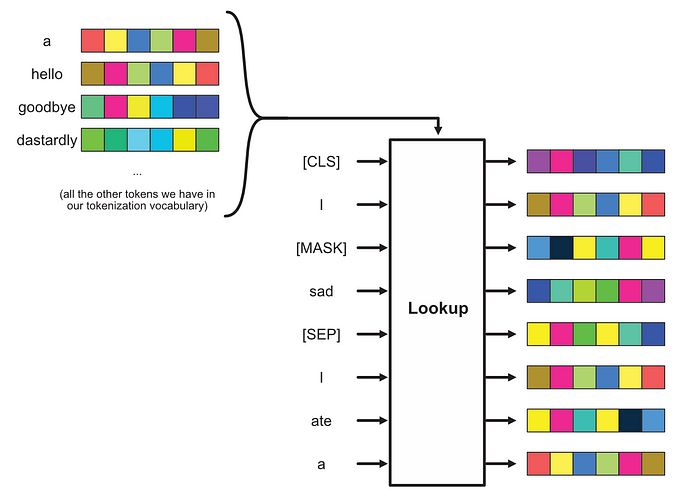
将标记序列转换为BERT中的向量序列的过程。这在许多变换器风格架构中是常见的方法。
与传统变换器一样,向量被添加到这些单词向量中,以嵌入有关单词位置的信息,但与原始变换器不同,BERT使用学习的位置信息编码。基本上,我们为输入序列中的每个位置创建一个随机向量,并将其添加到单词向量中。这些位置向量在训练期间也会更新。
在标记化查找表的基础上,我们还为输入序列中的每个位置创建向量,并将其添加到单词向量中。这使得模型能够学习表示单词的含义以及这些单词的位置。
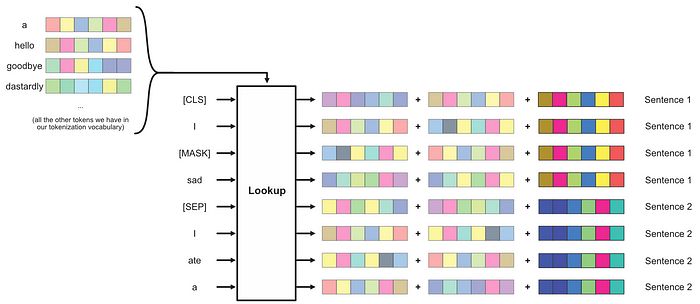
这在现代变换器中是一种常见的通用策略,但BERT还为每个单词添加了另一个向量,表示该单词属于哪个句子,这并不是特别典型的。
BERT中还进行了句子级嵌入。为每个句子创建随机向量并添加,以让模型知道一个单词来自哪个句子。
一旦单词和位置信息被编码,序列就会通过传统的编码器风格变换器块,生成输入的抽象和复杂的输出。我们将在实现中详细讨论这一点。
带有位置和句子嵌入的单词向量通过一个或多个编码器块,创建输入的密集且富有意义的表示。
然后,在BERT中,输入通过编码器块后会同时发生两件事:
- 输出中与
[CLS]标记对应的向量通过一个密集网络,生成一个预测,判断第二个句子是否跟随第一个句子。 - 所有掩码标记通过神经网络,以预测掩码的原始单词。
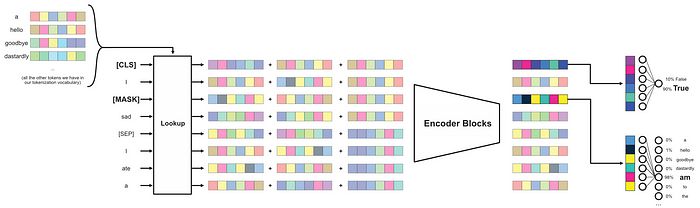
BERT风格模型的输入和输出的概念图。在最后,输出中与[CLS]标记对应的部分将用于下一个句子预测,而任何掩码标记(在这种情况下只有一个)将通过一个密集网络生成标记预测。
自然地,一个全新的模型在这两方面都表现不佳,但通过在许多示例上更新模型的参数,模型开始足够理解语言,以解决这两个问题。更重要的是,擅长解决这些问题自然赋予了模型对语言的理解,这可以在进一步的任务中利用。

从头实现BERT
我们已经涵盖了所有高层次的概念,现在让我们构建一个BERT模型。
我们将使用PyTorch构建并在维基百科文章的数据上预训练我们的BERT模型 (许可证)。然后,我们将在情感分析任务上微调我们的模型 (许可证)。
完整代码可以在 这里找到。
设置维基百科预训练数据集
好的,我们将使用Huggingface的出色datasets库来下载数据。我们还将使用nltk(自然语言工具包)按句子划分维基百科文章。
!pip install datasets
!pip install nltk
维基百科数据集相当大,我不想在玩这个文章时等待,所以我选择以流式模式加载数据集,以便我可以获取数据的子集。
from datasets import load_dataset
# 数据集很大,为了简化操作,我们将流式加载一个子集
dataset = load_dataset("wikipedia", "20220301.en", trust_remote_code=True, streaming=True)
我还将通过nltk安装punkt,这是一个我们将用来从文章中提取句子的句子标记器。
import nltk
nltk.download('punkt')
现在我们可以下载一些数据并提取一些句子。
"""将维基百科文章分解为句子和段落
"""
import itertools
num_articles = 10000
# 获取n篇文章
articles = list(itertools.islice(dataset_iter, num_articles))
# 获取段落
paragraphs = []
for article in articles:
paragraphs.extend(article['text'].splitlines())
# 过滤段落,以确保它们实际上是段落
paragraps = [p for p in paragraphs if len(p) > 50]
# 将段落分解为句子
divided_paragraphs = []
for p in paragraphs:
divided_paragraphs.append(nltk.sent_tokenize(p))
# 仅使用包含3个或更多句子的段落
divided_paragraphs = [pls for pls in divided_paragraphs if len(pls) >= 3]
divided_paragraphs
你可能会注意到,我首先沿着换行符将文章分解为段落,然后使用nltk将这些段落转换为句子,并且我只使用包含三个或更多句子的段落。这只是一些我实验过的简单数据工程,通常能让我获得不错的数据。在这段代码的最后,我们得到了divided_paragraphs,这是一个段落的列表,每个段落本身又是一个句子的列表。
# divided_paragraphs的内容
[['无政府主义是一种政治哲学和运动,怀疑权威并拒绝所有非自愿、强制性的等级形式。',
'无政府主义呼吁废除国家,认为国家是不必要的、不受欢迎的和有害的。',
'作为一种历史上左翼运动,位于政治光谱的最左端,通常与公社主义和自由主义马克思主义一起被描述为社会主义运动的自由主义翼(自由社会主义),并与反资本主义和社会主义有着强烈的历史关联。'],
['人类在没有正式等级的社会中生活,早于正式国家、王国或帝国的建立。',
'随着有组织的等级体的兴起,对权威的怀疑也随之增加。',
'尽管在历史上可以找到无政府主义思想的痕迹,但现代无政府主义是从启蒙时代开始的。',
'在19世纪后半叶和20世纪的头几十年,无政府主义运动在世界大部分地区蓬勃发展,并在工人争取解放的斗争中发挥了重要作用。',
'在这一时期,形成了各种无政府主义思想流派。',
'无政府主义者参与了几次革命,最著名的是巴黎公社、俄国内战和西班牙内战,其结束标志着无政府主义的经典时代的结束。',
'在20世纪的最后几十年和21世纪初,无政府主义运动再次复兴。'],
...
]
这对许多原因都很有用。原始文章的数据有点杂乱,包含许多语法错误的内容,这在网站上是有意义的,但在文本格式中却没有意义。通过仅保留段落,我们可以相当确定段落内的句子确实以一种有意义的方式相互跟随。
现在,我们实际上可以使用这些数据来制作正面和负面的句子对,其中一半的句子对是属于同一段落的,另一半则不是。
"""使用段落数据构建相互跟随的句子对和随机句子对
"""
import random
positive_pairs = []
negative_pairs = []
num_paragraphs = len(divided_paragraphs)
for i, paragraph in enumerate(divided_paragraphs):
for j in range(len(paragraph) - 1):
positive_pairs.append((paragraph[j], paragraph[j + 1]))
rand_par = i
while rand_par == i:
rand_par = random.randint(0, num_paragraphs - 1)
rand_sent = random.randint(0, len(divided_paragraphs[rand_par]) - 1)
negative_pairs.append((paragraph[j], divided_paragraphs[rand_par][rand_sent]))
在这段代码的最后,我们得到了两个句子对的列表,一个列表包含属于同一段落的句子,另一个则不包含。
# positive_pairs
[('无政府主义是一种政治哲学和运动,怀疑权威并拒绝所有非自愿、强制性的等级形式。',
'无政府主义呼吁废除国家,认为国家是不必要的、不受欢迎的和有害的。'),
('无政府主义呼吁废除国家,认为国家是不必要的、不受欢迎的和有害的。',
'作为一种历史上左翼运动,位于政治光谱的最左端,通常与公社主义和自由主义马克思主义一起被描述为社会主义运动的自由主义翼(自由社会主义),并与反资本主义和社会主义有着强烈的历史关联。'),
('人类在没有正式等级的社会中生活,早于正式国家、王国或帝国的建立。',
'随着有组织的等级体的兴起,对权威的怀疑也随之增加。'),
('随着有组织的等级体的兴起,对权威的怀疑也随之增加。',
'尽管在历史上可以找到无政府主义思想的痕迹,但现代无政府主义是从启蒙时代开始的。'),
('尽管在历史上可以找到无政府主义思想的痕迹,但现代无政府主义是从启蒙时代开始的。',
'在19世纪后半叶和20世纪的头几十年,无政府主义运动在世界大部分地区蓬勃发展,并在工人争取解放的斗争中发挥了重要作用。'),
('在19世纪后半叶和20世纪的头几十年,无政府主义运动在世界大部分地区蓬勃发展,并在工人争取解放的斗争中发挥了重要作用。',
'在这一时期,形成了各种无政府主义思想流派。'),
('在这一时期,形成了各种无政府主义思想流派。',
'无政府主义者参与了几次革命,最著名的是巴黎公社、俄国内战和西班牙内战,其结束标志着无政府主义的经典时代的结束。'),
...
]
# negative_pairs
[('无政府主义是一种政治哲学和运动,怀疑权威并拒绝所有非自愿、强制性的等级形式。',
'威克利夫派关于圣餐的教义在1382年的黑修道院会议上被宣布为异端。'),
('无政府主义呼吁废除国家,认为国家是不必要的、不受欢迎的和有害的。',
'虽然埃尔多安宣称反对反犹太主义,但他在公开声明中被指控使用反犹太主义的刻板印象。'),
('人类在没有正式等级的社会中生活,早于正式国家、王国或帝国的建立。',
'在1939年,德米尔的《联合太平洋》通过德米尔与联合太平洋铁路的合作而成功。'),
('随着有组织的等级体的兴起,对权威的怀疑也随之增加。',
'父亲和儿子各自拥有相同的双重名字,或者亚比亚撒在父亲的生前和父亲的名义下担任职务——这些观点得到了许多伟大人物的支持,但并未被完全接受。'),
('尽管在历史上可以找到无政府主义思想的痕迹,但现代无政府主义是从启蒙时代开始的。',
'常见的常规双重例子是低水平的套牌出价,暗示对未出价的花色或未出价的主要花色的支持,并要求搭档选择其中之一。'),
('在19世纪后半叶和20世纪的头几十年,无政府主义运动在世界大部分地区蓬勃发展,并在工人争取解放的斗争中发挥了重要作用。',
'20世纪30年代和40年代的特点是动荡和民粹主义政治家的崛起,例如五次总统何塞·玛丽亚·维拉斯科·伊巴拉。'),
...
]
通过这些,我们几乎已经设置好了预训练的数据集。
标记化
为了将数据输入到我们的模型中,我们需要以某种方式将句子转换为向量。在这方面,我们将使用Huggingface的预训练标记器。基本上,制作这个标记器的人查看了一些文本,并找出了文本中最常见的组成部分,然后将这些文本组成部分定义为“词汇”。我们可以用它将文本分解为单独的标记。
首先,我们下载标记器,
from transformers.models.bert.tokenization_bert_fast import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("google-bert/bert-base-uncased")
然后可以将一个示例句子放入标记器中,看看它是如何工作的。
"""玩弄标记器
"""
sentence = "这是一个奇怪的词:Withoutadoubticus。"
print(f'原始句子: "{sentence}"')
demo_tokens = tokenizer([sentence])
print(f"标记ID: {demo_tokens['input_ids']}")
tokens = tokenizer.convert_ids_to_tokens(demo_tokens['input_ids'][0])
print(f'标记值: {tokens}')
原始句子: "这是一个奇怪的词:Withoutadoubticus。"
标记ID: [[101, 2182, 1005, 1055, 1037, 6881, 2773, 1024, 2302, 9365, 12083, 29587, 1012, 102]]
标记值: ['[CLS]', 'here', "'", 's', 'a', 'weird', 'word', ':', 'without', '##ado', '##ub', '##ticus', '.', '[SEP]']
正如你所看到的,标记器将我们的句子分解为单独的组成部分,这可能包括将单个单词分解为多个组成部分。这被称为子词标记化,意味着标记器的词汇中既有单词也有单词组成部分。这一点很重要,因为它允许标记器将复杂的单词表示为一系列标记。
标记化并不是本文的重点,因此我们将其余部分视为理所当然。最终,标记器将文本序列转换为一堆数字。
探索特殊标记
由于我们使用的是为BERT风格模型预制的标记器,因此我们的标记器有一些实用标记供我们使用。
tokenizer
BertTokenizerFast(name_or_path='google-bert/bert-base-uncased', vocab_size=30522, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
- [PAD],
0,用于填充过短的句子,使我们能够填充模型的上下文长度。 - [UNK],
100,允许BERT用未知标记编码任何未知值。这可能是非ASCII字符,例如。 - [CLS],
101,一个特殊的类标记,我们将放在序列的开头。 - [SEP],
102,一个特殊标记,指定输入中句子之间的分隔。 - [MASK],
103,我们将用于掩盖输入数据的标记,使BERT能够通过掩码语言建模进行学习。
我们将在下一部分中使用这些标记来正确构建模型的输入。
定义训练批次
现在我们可以标记化数据,并了解我们可以使用哪些特殊标记,我们可以将正面和负面的句子对转换为我们可以用来训练模型的数据批次。
每个批次将包含128个单独的句子对示例,其中64个是正面对,64个是负面对。为了保持模型相对较小,加快训练速度,我们将模型的上下文窗口设置为64个标记。因此,在这个过程结束时,我们将得到一个张量,其形状为[number_of_batches x 128(batch_size) x 64(sequence_length)]。
这是我用来实现这一点的代码:
from tqdm import tqdm
import torch
from multiprocessing import Pool, cpu_count
# 定义数据所在的设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 批次中的示例数量
batch_size = 128 # 应该是2的倍数
# 模型的序列长度
max_input_length = 64
# 定义可并行处理的函数以处理批次
def process_batch(batch_index):
# 确定批次的边界
start_index = batch_index * batch_size
end_index = start_index + batch_size
if end_index > len(positive_pairs):
return None, None, None
# 获取批次的句子对,以及它们是正面还是负面
sentence_pairs = []
is_positives = []
# 创建正面对
sentence_pairs.extend(positive_pairs[start_index:start_index + int(batch_size / 2)])
is_positives.extend([1] * int(batch_size / 2))
# 创建负面对
sentence_pairs.extend(negative_pairs[start_index + int(batch_size / 2):end_index])
is_positives.extend([0] * int(batch_size / 2))
# 定义输出
# 最终我们需要知道三件事:
# - 批次中序列的标记
# - 标记属于哪个句子,用于位置编码
# - 批次中的示例是正面还是负面
# 这些跟踪前两者
batch_sentence_location_tokens = []
batch_sequence_tokens = []
# 标记化对
for sentence_pair in sentence_pairs:
sentence1 = sentence_pair[0]
sentence2 = sentence_pair[1]
# 标记化两个句子
tokens = tokenizer([sentence1, sentence2])
sentence1_tokens = tokens['input_ids'][0]
sentence2_tokens = tokens['input_ids'][1]
# 修剪标记
if len(sentence1_tokens) + len(sentence2_tokens) > max_input_length:
sentence1_tokens = [101] + sentence1_tokens[-int(max_input_length / 2) + 1:]
sentence2_tokens = sentence2_tokens[:int(max_input_length / 2) - 1] + [102]
# 创建句子标记
sentence_tokens = [0] * len(sentence1_tokens) + [1] * len(sentence2_tokens)
# 组合并填充
pad_num = max_input_length - (len(sentence1_tokens) + len(sentence2_tokens))
sequence_tokens = sentence1_tokens + sentence2_tokens + [0] * pad_num
sentence_location_tokens = sentence_tokens + [1] * pad_num
# 添加到批次
batch_sequence_tokens.append(sequence_tokens)
batch_sentence_location_tokens.append(sentence_location_tokens)
return torch.tensor(batch_sentence_location_tokens), torch.tensor(batch_sequence_tokens), torch.tensor(is_positives)
# 确定批次的数量
num_batches = len(positive_pairs) // batch_size
# 使用与CPU核心数量相等的工作池
with Pool(processes=cpu_count()) as pool:
results = list(tqdm(pool.imap(process_batch, range(num_batches)), total=num_batches))
# 过滤掉process_batch函数的None结果
results = [result for result in results if result[0] is not None]
# 解包结果到批次中
sentence_location_batches, sequence_tokens_batches, is_positives_batches = zip(*results)
# 将张量堆叠到最终批次中
sentence_location_batches = torch.stack(sentence_location_batches).to(device)
sequence_tokens_batches = torch.stack(sequence_tokens_batches).to(device)
is_positives_batches = torch.stack(is_positives_batches).to(device)
这段代码有点长,随意查看。大部分只是移动数据,所以我认为没有必要描述每一个细节。然而,我认为讨论这段代码中构建最终输入模型的部分是有用的。
# 修剪标记
if len(sentence1_tokens) + len(sentence2_tokens) > max_input_length:
sentence1_tokens = [101] + sentence1_tokens[-int(max_input_length / 2) + 1:]
sentence2_tokens = sentence2_tokens[:int(max_input_length / 2) - 1] + [102]
在这里,我有两个标记化的句子,我让它们都适应模型的序列长度。如果句子太长,我选择保留第一个句子的结尾和第二个句子的开头。这仍然应该允许长输入被模型合理地理解。
# 创建句子标记
sentence_tokens = [0] * len(sentence1_tokens) + [1] * len(sentence2_tokens)
在这里,我创建了一个向量,其中第一个句子的长度为零,第二个句子的长度为一。我们将使用这个向量在构建模型时帮助我们进行位置编码。
# 组合并填充
pad_num = max_input_length - (len(sentence1_tokens) + len(sentence2_tokens))
sequence_tokens = sentence1_tokens + sentence2_tokens + [0] * pad_num
sentence_location_tokens = sentence_tokens + [1] * pad_num
然后我们构建输出。我们将句子标记组合在一起,如果组合的长度小于模型长度,我们就添加一些填充标记。如果我们确实添加了填充标记,我们就说填充标记属于第二个句子,以方便起见。因此,概念上,事件的顺序看起来像这样:
# 示例句子
sentence1 = '你好,世界!'
sentence2 = '这是一个示例!'
# 分解为标记
sentence1_tokens = ['[CLS]', '你好', ',', '世界', '!']
sentence2_tokens = ['[CLS]', '这是', '一个', '示例', '!']
# 这些标记有ID
sentence1_token_ids = [101, 1340, 87345, 1332]
sentence2_token_ids = [101, 4589, 988, 874, 13598, 1332]
# 我们可以将标记ID组合在一起,并在它们之间添加填充。
# 另外,我们不需要第二个句子的CLS标记
sequence_token_ids = [101, 1340, 87345, 1332, 102, 4589, 988, 874, 13598, 1332]
# 构建位置标记以进行位置编码
# 注意它们与序列标记ID的对应关系
sent_location_tokens = [0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
# 如果需要,填充0的标记ID和1的句子位置
说实话,我没有花太多时间验证这段代码。在写作过程中,我意识到有一些小问题会导致各种序列的标记不一致。我将其留作读者的练习。实际上,如果我们构建一个能够理解自然语言的模型,它应该足够聪明以处理一些小的格式问题。如果你想自己构建一个超级强大的BERT模型,可能需要美化这段代码。
无论如何,最终我们得到了每个句子的标记ID序列的批次,每个序列对应于两个句子,我们得到了一个向量,用于编码标记属于第一个句子还是第二个句子,并且我们还跟踪了批次中这些示例是正面还是负面。
# 我们拥有的数据的概念性分解
# 形状: [num_batches x batch_size x seq_length]
batch_tokens = [
[101, 1100, 87345, 1332, 102, 4589, 988, 874, 13598, 1332, 0, 0, 0],
[101, 987, 1332, 87345, 873, 4589, 102, 874, 13598, 1332, 1399, 1324, 1246],
...
]
# 形状: [num_batches x batch_size x seq_length]
batch_location = [
[0,0,0,0,1,1,1,1,1,1,1,1,1],
[0,0,0,0,0,0,1,1,1,1,1,1,1],
...
]
# 形状: [num_batches x batch_size]
batch_is_positive_labels = [
1,
0
]
创建掩码函数
回想一下,BERT在两个建模目标上同时进行训练:下一个句子预测和掩码语言建模。我们已经拥有了第一个目标所需的所有数据,因此现在我们需要构建第二个目标。
我略过了一些掩码语言建模的细节;现在让我们来讨论这些细节。
细节1
基本上,想法是接收某个序列,随机掩盖某些标记,然后让模型根据周围的文本猜测该标记应该是什么。
The [MASK] brown fox jumped over the lazy [MASK]
因此,我们将构建一个函数,该函数接收输入序列并随机掩盖该序列中的值。我们的输入序列比简单句子复杂得多,我们有一个对应于两个句子的标记列表,并包含特殊标记。
[CLS] Here's a famous sentence. [SEP] The quick brown fox jumped over the lazy dog. [pad] [pad] [pad]
在构建掩码函数时,我们不想无意中掩盖特殊标记,如[CLS]、[SEP]和[PAD]。我们只想掩盖与句子本身对应的标记。
细节2
在我们开始之前,还有另一个值得注意的细节。在BERT论文中,他们实际上并不总是用[MASK]标记替换每个掩盖的单词。
在训练模型后,模型在实际使用和推理时将永远不会看到[MASK]标记。如果我们只训练模型使用[MASK]标记,它可能会学会忽视其他可能在理解序列中重要的单词。因此,当我们决定随机掩盖一个标记时,我们通常用[MASK]标记替换它,但我们有时会保留原始标记的值,有时会用完全随机的标记替换掩盖的标记。
这个想法是,这应该使模型更批判性地思考输入,并考虑每个标记,而不仅仅是[MASK]标记,都是重要的。
# 概念性分解,掩盖而不总是使用掩码标记
orig_sequence = 'The quick brown fox jumped over the lazy dog.'
masked_sequence = 'The [MASK] brown fox jumped over the lazy asparagus'
masked_tokens = ['[MASK]', 'fox', 'asparagus']
original_toks = ['quick', 'fox', 'dog']
我希望这个例子能让这个概念更清晰。在这里,我们掩盖了三个单词,“quick”、“fox”和“dog”,但通过不总是使用掩码标记,掩码语言建模目标变得更加丰富,因为模型还需要确认某些单词是否有意义,而其他单词在输入的上下文中则没有意义。在原始BERT论文中,他们决定掩盖15%的单词。在这15%中,80%被替换为[MASK],10%被替换为随机单词,10%则不被替换。我们将在实现中使用这些概率。
实现掩码
好的,我们涵盖了细节,现在是掩码代码:
# 列出随机标记掩盖的词汇
vocab = tokenizer.get_vocab()
valid_token_ids = list(vocab.values())
def mask_batch(batch_tokens, clone=True):
if clone:
batch_tokens = torch.clone(batch_tokens)
# 定义可能掩盖的标记的百分比
replace_percentage = 0.15
# 定义不应被替换的标记
excluded_tokens = {0, 100, 101, 102, 103}
# 创建掩码以识别可以替换的标记
eligible_mask = ~torch.isin(batch_tokens, torch.tensor(list(excluded_tokens)).to(device))
# 计算合格标记的数量
num_eligible_tokens = eligible_mask.sum().item()
# 计算可能掩盖的标记数量
num_tokens_to_mask = int(num_eligible_tokens * replace_percentage)
# 创建合格标记索引的随机排列
eligible_indices = eligible_mask.nonzero(as_tuple=True)
random_indices = torch.randperm(num_eligible_tokens)[:num_tokens_to_mask]
# 创建替换的概率分布
replacement_probs = torch.tensor([0.8, 0.1, 0.1]) # 对应于 [103, 随机标记, 保持不变]
replacement_choices = torch.multinomial(replacement_probs, num_tokens_to_mask, replacement=True)
# 存储标记是否被掩盖的向量(0:未掩盖,1:已掩盖)
masked_indicator = torch.zeros_like(batch_tokens, dtype=torch.int32)
# 根据采样选择应用替换
for i, idx in enumerate(random_indices):
row = eligible_indices[0][idx]
col = eligible_indices[1][idx]
# 用[MASK]替换
if replacement_choices[i] == 0:
batch_tokens[row, col] = 103
masked_indicator[row, col] = 1
# 用随机标记替换
elif replacement_choices[i] == 1:
batch_tokens[row, col] = random.choice(valid_token_ids)
masked_indicator[row, col] = 1
# 不替换
elif replacement_choices[i] == 2:
masked_indicator[row, col] = 1
return batch_tokens, masked_indicator
batch_tokens, masked_indicator = mask_batch(sequence_tokens_batches[0])
batch_tokens
这个函数最终输出掩盖的标记和掩盖标记的位置。因为“掩盖”标记可能并不总是[MASK]标记,我们需要单独跟踪掩盖标记的位置。
嵌入
好的,我们已经完成了设置训练数据集所需的所有准备工作。我们有批次的标记、关于这些标记属于哪个句子的位置信息(句子1或句子2)、这些对是否属于同一对的跟踪信息,以及一个可以接收标记并掩盖它们的函数。
现在我们可以开始构建模型。
第一步是嵌入。BERT风格模型作为变换器的衍生物,期望每个单词用高维向量表示。模型将使用这些向量进行推理,从而(希望)对输入文本形成强大的理解。因此,我们需要将标记(仅为整数)转换为这些高维向量。
回想一下,在BERT风格模型中,我们结合来自单词、位置和句子的向量,为输入中的每个元素构建一个向量。
模型的嵌入部分将负责将标记转换为向量,并通过使用查找表添加位置信息。我们将为每个可能的标记定义随机向量,为每个输入位置定义随机向量,并为两个句子输入定义随机向量。我们将用这些随机向量替换标记和位置,并用它们表示标记及其位置。自然地,最开始它的表现会很差,因为我们使用的是完全随机的数据,但这些随机值将是模型的可学习参数,因此模型将学习如何为标记和位置编码创建良好的向量。
以下是实现这一点的PyTorch代码:
import torch.nn as nn
import torch
vocab_size = tokenizer.vocab_size
d_model = 256
n_segments = 2
class Embedding(nn.Module):
def __init__(self):
super(Embedding, self).__init__()
self.tok_embed = nn.Embedding(vocab_size, d_model) # 标记嵌入
self.pos_embed = nn.Embedding(max_input_length, d_model) # 位置嵌入
self.seg_embed = nn.Embedding(n_segments, d_model) # 段(标记类型)嵌入
self.norm = nn.LayerNorm(d_model)
def forward(self, x, seg):
seq_len = x.size(1)
pos = torch.arange(seq_len, dtype=torch.long).to(device)
pos = pos.unsqueeze(0).expand_as(x) # (seq_len,) -> (batch_size, seq_len)
embedding = self.tok_embed(x) + self.pos_embed(pos) + self.seg_embed(seg)
return self.norm(embedding)
e = Embedding()
e.to(device)
在这里,我们表示单词的向量长度为256,参数d_model=256,并且我们处理两个句子,n_segments=2。如果你想尝试更多的句子输入,当然可以,但在这个例子中我们保持在两个句子。
我们可以将一批数据传入这个模块,看看我们得到什么。
dummy_embedding = e(sequence_tokens_batches[0], sentence_location_batches[0])
print(dummy_embedding.shape)
print(dummy_embedding)
torch.Size([128, 64, 256])
tensor([[[-0.4109, 0.1544, 0.3778, ..., -1.9995, 1.3578, 0.3117],
[-0.5452, -0.7935, -0.6296, ..., 1.0046, -0.1871, -0.3125],
[-2.2820, 0.4665, -1.1026, ..., -0.5876, 1.4205, -1.5876],
...,
[ 1.2866, 0.9395, 0.7138, ..., 0.4223, 0.3374, 0.6935],
[-0.3787, 1.4489, -0.7226, ..., 0.3139, 0.3640, 0.4926],
[ 1.1291, 1.4248, -0.2899, ..., 0.8080, 0.7977, 1.4257]],
[[-0.4109, 0.1544, 0.3778, ..., -1.9995, 1.3578, 0.3117],
[-0.9470, -0.4977, -1.0789, ..., 0.5366, 0.5290, -1.7874],
[-1.5527, -0.2966, -0.3398, ..., -0.5468, 1.3547, -0.6128],
...,
[ 1.2866, 0.9395, 0.7138, ..., 0.4223, 0.3374, 0.6935],
[-0.3787, 1.4489, -0.7226, ..., 0.3139, 0.3640, 0.4926],
[ 1.1291, 1.4248, -0.2899, ..., 0.8080, 0.7977, 1.4257]],
[[-0.4109, 0.1544, 0.3778, ..., -1.9995, 1.3578, 0.3117],
[-0.9972, 0.2936, -0.3921, ..., 0.1695, -0.2766, -1.4312],
[-2.2029, -1.5211, -1.3297, ..., -0.6648, 2.2392, -0.1643],
...,
[ 1.2866, 0.9395, 0.7138, ..., 0.4223, 0.3374, 0.6935],
[-0.3787, 1.4489, -0.7226, ..., 0.3139, 0.3640, 0.4926],
[ 1.1291, 1.4248, -0.2899, ..., 0.8080, 0.7977, 1.4257]],
...,
这看起来不错!批次大小为128,序列长度为64,但现在每个标记用长度为256的向量表示。请记住,这个输出仅对应于一个批次。
多头自注意力
这一部分更深入,假设你对多头自注意力有相当的了解。如果你是新手,可以随意浏览或跳过这部分,理解BERT整体并不根本。如果你想更好地理解这一部分,可以查看我关于 变换器 和我关于 多头自注意力 的文章。
BERT是一个变换器风格的模型,因此多头自注意力是一个关键组件。由于它至关重要,我们将从头实现它。为什么不呢。
到目前为止,我已经多次介绍多头自注意力(MHSA),这个主题和我就像老朋友一样,意外地看到彼此裸体的次数太多,以至于我们知道彼此的屁股形状。如果你觉得“哇,这太多信息了,就像那个比喻一样”,那么使用PyTorch的MHSA 实现。 它更高效。
对于勇敢者,让我们开始。
首先,我们可以实现一个单一的注意力头。我们假设查询、键和值已经创建,因此我们可以快速实现。这个没有任何可学习的参数,这些参数将在多头自注意力机制中使用,后者将使用这个作为子组件。
import numpy as np
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V):
# Q, K, V的大小为[batch x sequence_length x dim]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(Q.shape[1])
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
# 检查正确性
q = torch.tensor([[[1.1,1.3],[0.9,0.8]]]).to(device)
k = torch.tensor([[[0.9,1],[0.2,2.1]]]).to(device)
v = torch.tensor([[[1.1,1.3],[0.9,0.8]]]).to(device)
sample = ScaledDotProductAttention().to(device)
sample(q,k,v)
(tensor([[[0.9771, 0.9927],
[0.9912, 1.0280]]], device='cuda:0'),
tensor([[[0.3854, 0.6146],
[0.4559, 0.5441]]], device='cuda:0'))
对于熟悉MHSA的人来说,请注意没有掩码。如果你使用预制的MHSA实现,你几乎肯定需要指定某种形式的掩码,因为MHSA几乎总是在需要掩盖注意力的上下文中使用。在BERT中,我们希望每个输入标记都能关注其他所有输入标记,因此我们根本不需要掩码。
实际上,将其转化为多头自注意力有点麻烦,主要是因为无聊的数据工程原因。我们有一批示例需要转换为查询、键和值,然后这些需要进一步划分为多个头。这意味着我们有效地有两个轴需要在自注意力中并行化;批次维度和新的头维度。
为了使其正常工作,我决定将这两个维度压缩为一个维度,并将批次和头维度的组合视为仅批次维度。因为PyTorch自动在第0维度上并行化,假设它是批次维度,我们可以通过将这两个维度压缩为一个维度,有效地在批次和头之间并行化自注意力。
在我实际实现MHSA之前,我玩了一些这些形状转换,实验了一些示例,并得出了一些(我认为)有效的结果。
# 定义示例值矩阵
#[batch_size x sequence_len x (query_key_dim * n_heads)]
# 在这个矩阵中,[0,1,2,3]表示一个单词向量的两个头的值
samp_val = torch.tensor([[[0,1,2,3],[4,5,6,7]],[[0,-1,-2,-3],[-4,-5,-6,-7]]])
# 划分为两个头
#[batch_size x sequence_len x query_key_dim x n_heads]
samp_val = samp_val.view(2,2,2,2)
# 将头维度移动到批次维度旁边
#[batch_size x n_heads x sequence_len x query_key_dim]
samp_val = samp_val.permute(0, 3, 1, 2)
# 组合批次和头维度
#[batch_size*n_heads x sequence_len x query_key_dim]
samp_val = samp_val.reshape(-1, 2, 2)
# 这将是mhsa的输入,输出的形状应该与输入相同
# 现在我想将mhsa的结果解包回原始形状
#[batch_size x sequence_len x (query_key_dim * n_heads)]
# 如果我做得对,值应该完全相同
# 分离头
#[batch_size x n_heads x sequence_len x query_key_dim]
samp_val = samp_val.reshape(2,2,2,2)
# 将头维度移动到最后
#[batch_size x sequence_len x query_key_dim x n_heads]
samp_val = samp_val.permute(0, 2, 3, 1)
# 将最后一个维度组合在一起,有效地连接头的结果
#[batch_size x sequence_len x query_key_dim*n_heads]
samp_val = samp_val.reshape(2, 2, -1)
samp_val
# 注意它与输入相同。这意味着
# 变换成功
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 0, -1, -2, -3],
[-4, -5, -6, -7]]])
现在我已经在概念上定义了这些转换,我可以用它们来构建MHSA。
import torch
import torch.nn as nn
# 定义常量
n_heads = 3
query_key_dim = 64
value_dim = 64
class MultiHeadSelfAttention(nn.Module):
def __init__(self):
super(MultiHeadSelfAttention, self).__init__()
# 定义构建查询、键和值的线性层
self.W_Q = nn.Linear(d_model, query_key_dim * n_heads) # 将输入投影到[batch x sequence x (q/k_dim*num_heads)]
self.W_K = nn.Linear(d_model, query_key_dim * n_heads) # 将输入投影到[batch x sequence x (q/k_dim

赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052