

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
使用 Chainlit 和 Mistral 创建最简单的 LLM 应用程序
5 个月前
我们之所以频繁讨论检索增强生成(Retrieval Augmentation Generation, RAG)和大型语言模型(Large Language Models, LLMs),是因为公司开发的 LLMs 仅限于创建它们时所用的知识。如果你想要某个主题的更具体或更新的信息,就需要采取一些措施。你可以选择对模型进行微调(fine-tune),或者通过 RAG 添加一些内容,而无需重新训练大型语言模型。
在这两种情况下,要实现一个完整的应用程序,通常需要以下组件:
- 前端,用于生成聊天界面(例如 Bootstrap、React 或一些 Nodejs 扩展)。
- API,用于连接前端和后端(即本列表的其余部分)。
- 自然语言处理(Natural Language Processing, NLP)协调器,用于处理思维链(chain of thoughts)。例如 Haystack。
- 向量数据库,如 Weaviate 或 Chromadb。
- 预训练的 LLM(如 ChatGPT、LLama、Mistral 等)。
如果你是全栈开发者,可能会对如何将这些东西组合在一起有一些想法。否则,还有更简单的解决方案:Chainlit。
Chainlit 是一个开源的异步 Python 框架,允许开发者构建可扩展的对话式 AI 或智能应用程序。
实际上,他们为我们完成了所有繁琐的工作。
他们创建了一个基于简单消息功能的简化界面。在底层,Chainlit 是基于 React 和 FastAPI 构建的,可以连接多个 LLM,管理思维链,如下图所示。
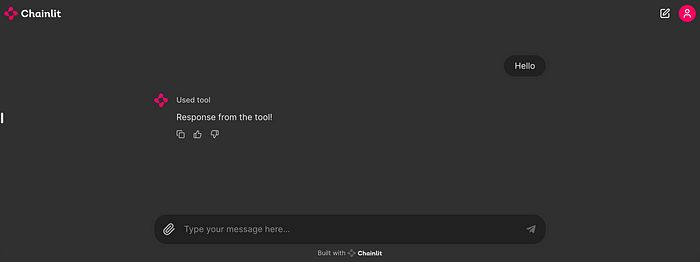
ChainLit 的 hello world 截图
在本文的其余部分,我将指导你如何创建一个简单但有效的基于 Chainlit 的 LLM 应用程序。你可以在这里找到视频教程:
要安装并在没有 RAG 的情况下使用它,我们只需要两个库,可以通过 pip 安装:
pip install chainlit
pip install transformers
在所有 LLM 中,我目前最喜欢 Mistral。这是因为它仅有 70 亿个参数,却能达到与其他更大模型相当的结果,并且是开源的。
我们有两种选择:
- 下载模型并在本地使用。
- 或者在线访问模型端点。
在这两种情况下,我们都需要从 Mistral 或 HuggingFace 获取 API 密钥。
为此,请访问 huggingface.co,创建一个个人资料并复制 API 密钥。
以下代码将从名为 HF_TOKEN 的环境变量中读取密钥。
在 Linux 中,你需要执行:
export HF_TOKEN=**************************************
其中星号代表你的密钥。
在我们的 LLM 应用中,我们只需导入两个库以及一个用于与环境变量交互的库:
import chainlit as cl
import requests
import os # 用于读取环境变量
然后我们可以加载密钥并指向在线模型端点:
# 从环境变量加载 Hugging Face API 密钥
HF_TOKEN = os.getenv("HF_TOKEN")
# 定义 API 端点和模型
API_URL = "https://api-inference.huggingface.co/models/mistralai/Mistral-7B-Instruct-v0.1"
接下来,我们只需要几个函数。一个用于发起 API 请求,另一个用于在 HTML 页面(前端)和模型之间进行消息传递:
# 辅助函数,用于发起 API 请求
def query_model(prompt: str) -> str:
headers = {"Authorization": f"Bearer {HF_TOKEN}"}
payload = {"inputs": prompt, "options": {"use_cache": False}}
response = requests.post(API_URL, headers=headers, json=payload)
response.raise_for_status() # 对 HTTP 问题引发错误
result = response.json()
return result[0]['generated_text']
# 聊天开始时运行
@cl.on_chat_start
def on_chat_start():
# 初始化或设置(如有需要)
pass
# 发送消息时运行
async def on_message(message: cl.Message):
# 准备提示
prompt = f"[INST]{message.content}[/INST]"
# 查询模型
try:
result = query_model(prompt)
# 过滤输出以去除提示或任何不需要的文本
filtered_result = result.replace(prompt, "").strip() # 从结果中移除提示
# 可选:如果还有其他不想要的文本,可以进一步精炼这一步。
await cl.Message(author="Bot", content=filtered_result).send()
except Exception as e:
await cl.Message(author="Bot", content=f"错误: {str(e)}").send()
就这样。
要运行应用程序,需要从终端运行 Python 脚本(以前称为 app.py):
chainlit run app.py
这将在浏览器中打开前端,整个应用程序在本地主机的 8000 端口运行。
前端将显示 Chainlit 的标志,以及底部的字符串“Powered by Chainlit”。不过,可以对其进行个性化。
我们需要在 Python 脚本旁边创建一个名为“public”的文件夹,将标志、CSS 和我们想要替换的其他内容放在那里。
要将应用程序部署到公共环境,我们需要将应用程序部署到本地主机以外的地方。
我们可以将应用程序放在云服务上(例如 AWS、Azure、Google Cloud),或者
将其放在某种隧道的本地机器上,以便在互联网上打开。
最简单的方法是使用 Ngrok 转发到本地主机的端口:
ngrok http 8000
Ngrok 将提供一个公共 URL(例如,https://abc123.ngrok.io)。这种方法直接将机器暴露在互联网上,请确保机器是安全的。
创建基于 Chainlit 的 LLM 应用程序是一种强大而高效的方式,可以利用对话式 AI,而不必被从头构建所有内容的复杂性所困扰。通过使用 Chainlit,你可以快速集成前端、API 和协调工具与预训练的 LLM(如 Mistral),使你能够专注于应用程序的核心功能。无论是使用 Ngrok 在本地部署,还是在云服务上,Chainlit 都简化了这一过程,使其对全栈开发者和新手都变得可及。只需几个步骤,你就可以构建、定制和部署一个满足特定需求的强大 AI 应用程序。
如果你喜欢这篇文章,请考虑分享给他人,并 注册我的邮件列表。
或者直接联系我:



推荐阅读:






赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052