

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
这些“少即是多”的提示词技巧你必须知道!
4 个月前
我在 LinkedIn 上看到了一篇帖子,两个朋友也分享了这篇帖子(这就是我发现它的原因)。这让我思考了一下,我觉得为了更清晰的理解,有必要对这个话题进行探讨和阐述。
我想先做一些初步的声明:
1 • 我理解 Ismail 正在 Flux 上尝试长提示——这是另一个生成 AI 的文本到图像平台——而不是 Midjourney。
2 • 在大量文字和看似奇妙的图像中,大多数人不会深入挖掘——因此不会意识到这实际上并没有奏效。
3 • 这次深入探讨并不是在攻击帖子、发帖者或分享者,而是我希望能提供一些清晰的见解。


这是 Ismail 帖子中创建和分享的图像。
我在帖子中做了这个评论——我在这里分享它,因为这是问题的关键。
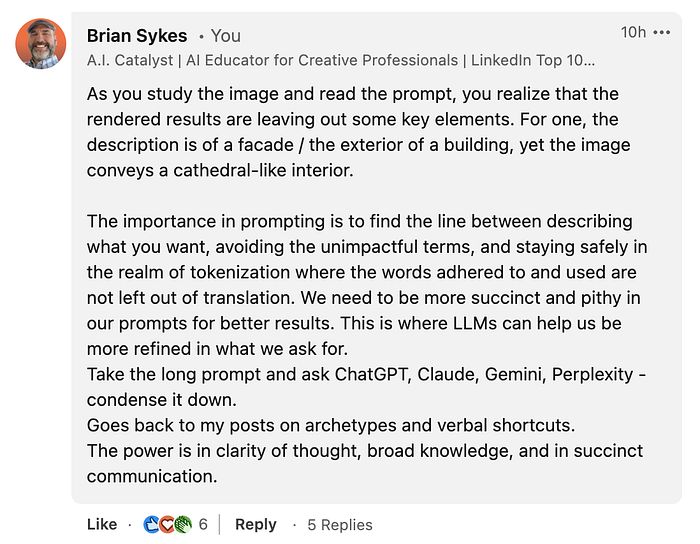
重点是什么?
在提示中,重要的是找到描述你想要的内容与避免无效术语之间的界限,并安全地保持在标记化的范围内,确保所使用的词汇不会在翻译中被遗漏。为了获得更好的结果,我们需要在提示中更加简洁和精炼。
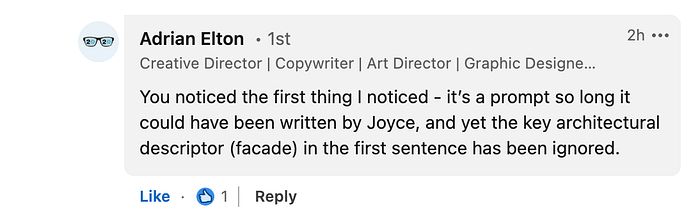
我的朋友 Adrian Elton 也注意到了我所发现的……这个非常长的提示在第一行的请求中并没有得到遵循。
我去 ChatGPT-4o -
使用我的 12 个提示元素框架,将以下描述修改为简洁而有力的提示。
我随后粘贴了 Ismail 的长提示,ChatGPT 回复了:

我将这个简化的提示格式带到 Midjourney,添加了纵横比和风格。

这些是 — ar 5:3 和 3:5。
我使用 ChatGPT-4o 修改了提示。关键在于,成功的提示和渲染并不是依赖于大量的文字,而是基于简洁地陈述你想要的内容的精炼方法。
查尔斯·狄更斯在他那个时代是按字数收费的,因此 多余的词 对他的作品是有用的。然而在提示中,我们希望尽可能简洁,以获得最佳结果,因此更加简洁和有力意味着,确实是 少即是多。
在与 ChatGPT 的对话中,我要求 ChatGPT 使用这个提示创建一幅图像。它在使用 Dall-E 渲染之前,通常会修改自己的提示。以下是它生成的内容:
创建一幅超现实主义、抽象、对称的远景图,展示一个超级未来派的住宅建筑外立面,融合华丽的巴洛克风格和大胆的粗犷主义建筑。突出复杂的巴洛克曲线和精致的装饰,与强大的粗犷主义几何形状无缝结合。使用大气、柔和的光线来增强反射和折射特性,使外立面看起来几乎是活的。模拟 35mm 胶卷照片,带有细腻的颗粒感和梦幻般的温暖,赋予其永恒的电影质感。在催眠的视觉体验中挑战观众的尺度和视角,展示未来世界的建筑创新。纵向格式。

当给出大量文字时,AI 会决定关注哪些内容。原因在于标记化、解释和应用。这些是 AI 处理文本输入的一些核心方面,尤其是在生成图像或执行其他复杂任务的背景下。
像 Flux(Ismail 使用的那个)、Midjourney,甚至 Dall-E 这样的 AI 模型会将输入文本分解为称为标记的小单元,这些标记可以是单词或单词的一部分。这些标记帮助模型理解和生成响应。模型在一次处理时有一个最大标记限制,这可能会影响它如何处理冗长的输入。
以下是简化的分解:
- 标记化:模型将文本拆分为可管理的部分(标记)。如果文本超过模型的标记限制,它可能不会考虑输入的某些部分。
- 解释:AI 根据其在大量文本数据上接受的训练来解释标记。它试图理解上下文和需要执行的具体任务。
- 应用:模型将其解释的内容应用于生成响应或创建新内容,例如图像。在此过程中,它会根据标记与任务的相关性优先考虑某些标记。
当你提供大量详细信息时,例如图像的冗长提示,AI 旨在捕捉请求的本质,但可能会更关注某些方面而非其他方面。这不仅仅是一个限制,也是确保最关键元素(AI 理解的)得到处理的一种方法。
因此,虽然 AI 在一次处理时有实际的限制,但这也与 AI 如何在其能力和特定任务的背景下解释和优先考虑信息有关。
推荐阅读:






赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052