

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
这个 Pandas 替代品在处理 1 亿行时快了 350 倍
4 个月前
每个人都知道 Pandas。对于数据分析的新手来说,这是一个不错的库,但如果你想处理大量数据,它是最慢的选择之一。
引入 DuckDB — 一个开源的、嵌入式的、内存中的关系 OLAP 数据库管理系统。虽然听起来有很多术语,但本质上,它是一个在内存中运行的分析型列式数据库,旨在提供速度和效率。与 Pandas 相比,它的速度快了几个数量级,尤其是在处理大数据集时。
最棒的部分? DuckDB 有一个 Python 库,这意味着你可以迅速替换掉慢吞吞的 Pandas 聚合,尤其是如果你熟悉 SQL 的话。
今天你将看到这两者在聚合超过 1 亿行数据时的比较。让我们开始吧!
Pandas vs. DuckDB 基准测试设置
本节提供基准测试的数据集和 Pandas/DuckDB 代码。作为参考,我使用的是 M2 Pro MacBook Pro 12/19 核心,配备 16 GB 内存,因此你的结果可能会有所不同。
数据集信息
今天我将使用以下数据集:
- 纽约市出租车和豪华轿车委员会 (TLC) 行程记录数据,于 2024 年 4 月 18 日访问,来源于 https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page。数据是免费使用的。许可证信息可以在 nyc.gov 找到。
更具体地说,我下载了从 2021 年 1 月到 2024 年 1 月的每月黄出租车数据。单个 Parquet 文件占用 1.79 GB 的磁盘空间:
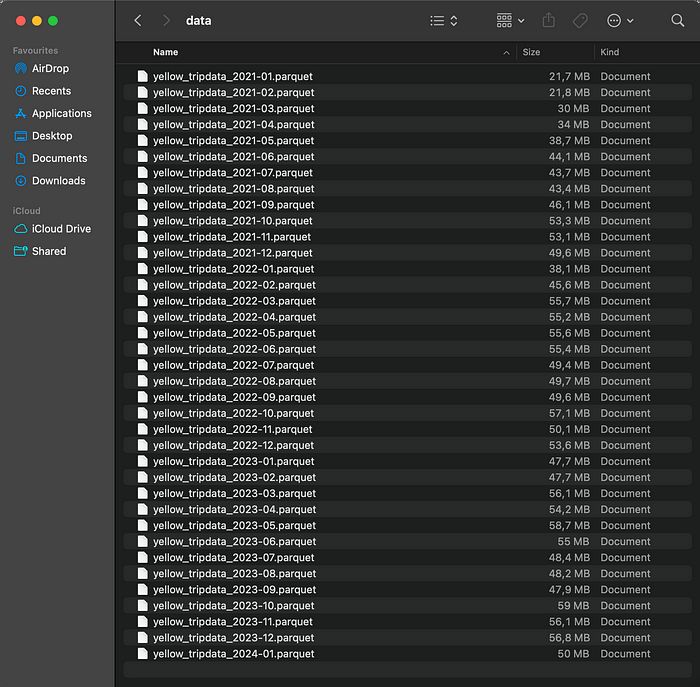
图 1 — Parquet 格式的出租车数据(作者提供)
基准测试目标
基准测试的目标是首先使用 Pandas/DuckDB 加载 Parquet 文件,然后计算每月统计数据,例如行程数量、平均时长、距离、费用和小费金额。为了找到这些数据,你需要创建几个日期时间列,根据日期范围过滤结果,并在 Pandas 中处理多级索引。
一旦数据加载完成,你会发现你正在处理超过 1.11 亿条记录:

图 2 — 加载的数据集形状(作者提供)
最终你希望得到以下 DataFrame:
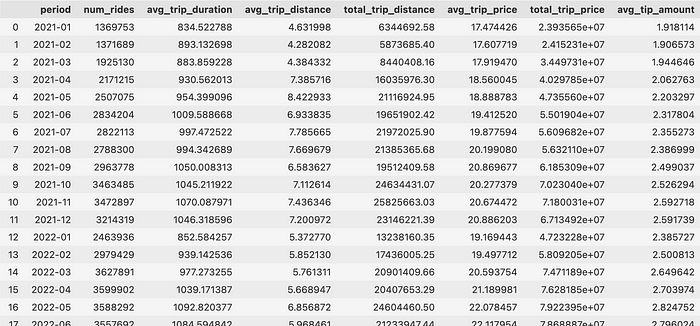
图 3 — 结果 DataFrame(作者提供)
所以每月的平均值和总和 — 没什么花哨的。然而,由于数据量庞大,计算将需要一些时间。
Pandas 设置
Pandas 是一个单线程库,旨在方便使用,而不是快速处理大量数据。它首先需要将所有数据加载到内存中,而在处理 Parquet 文件时,它需要逐个读取。这并不好。
你还需要处理重置多级索引的麻烦,以便更容易访问单独的列:
import os
import pandas as pd
# 加载数据
base_path = "path/to/the/folder"
parquet_files = [os.path.join(base_path, file) for file in os.listdir(base_path) if file.endswith('.parquet')]
dfs = [pd.read_parquet(file) for file in parquet_files]
df_pd = pd.concat(dfs, ignore_index=True)
# 基准测试函数
def calculate_monthly_taxi_stats_pandas(df: pd.DataFrame) -> pd.DataFrame:
df = (
df
.assign(
trip_year=df["tpep_pickup_datetime"].dt.strftime("%Y").astype("int32"),
period=df["tpep_pickup_datetime"].dt.strftime("%Y-%m"),
trip_duration=(df["tpep_dropoff_datetime"] - df["tpep_pickup_datetime"]).dt.total_seconds()
)
.query(f"trip_year >= 2021 and trip_year <= 2024")
.loc[:, ["period", "trip_duration", "trip_distance", "total_amount", "tip_amount"]]
.groupby("period")
.agg({
"trip_duration": ["count", "mean"],
"trip_distance": ["mean", "sum"],
"total_amount": ["mean", "sum"],
"tip_amount": ["mean"]
})
)
df.columns = df.columns.get_level_values(level=1)
df = df.reset_index()
df.columns = ["period", "num_rides", "avg_trip_duration", "avg_trip_distance", "total_trip_distance", "avg_trip_price", "total_trip_price", "avg_tip_amount"]
df = df.sort_values(by="period")
return df
# 运行
res_pandas = calculate_monthly_taxi_stats_pandas(df=df_pd)
DuckDB 设置
有多种方式可以通过 Python 与 DuckDB 交互,但最简单的方法是使用类似 SQL 的命令。实际上,你可以用两个 SELECT 语句来复制上述 Pandas 代码。
此外,DuckDB 提供了一个 neat 的 parquet_scan() 函数,可以并行读取给定路径下的所有 Parquet 文件:
import duckdb
# 数据库连接
conn = duckdb.connect()
# 基准测试函数
def calculate_monthly_taxi_stats_duckdb(conn: duckdb.DuckDBPyConnection, path: str) -> pd.DataFrame:
return (
conn.sql(f"""
select
period,
count(*) AS num_rides,
round(avg(trip_duration), 2) AS avg_trip_duration,
round(avg(trip_distance), 2) AS avg_trip_distance,
round(sum(trip_distance), 2) as total_trip_distance,
round(avg(total_amount), 2) as avg_trip_price,
round(sum(total_amount), 2) as total_trip_price,
round(avg(tip_amount), 2) as avg_tip_amount
from (
select
date_part('year', tpep_pickup_datetime) as trip_year,
strftime(tpep_pickup_datetime, '%Y-%m') as period,
epoch(tpep_dropoff_datetime - tpep_pickup_datetime) as trip_duration,
trip_distance,
total_amount,
tip_amount
from parquet_scan("{path}")
where trip_year >= 2021 and trip_year <= 2024
)
group by period
order by period
""").df()
)
# 运行
res_duckdb = calculate_monthly_taxi_stats_duckdb(conn=conn, path="path/to/the/folder/*parquet")
这就是你的设置!现在,让我们来看看结果。
基准测试结果 — DuckDB 比 Pandas 快 352 倍
准备好结果了吗?本节的标题已经说明了一切:
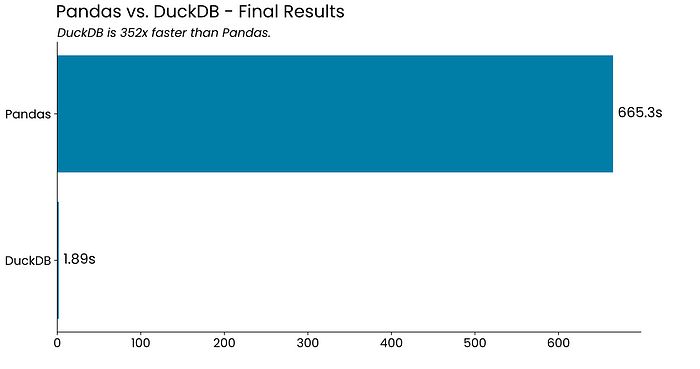
图 4 — Pandas vs. DuckDB — 运行时间结果(作者提供)
这真是不可思议。 在不到两秒的时间内聚合超过 1 亿行数据的能力似乎不真实,但数据不会说谎。
如果你能接受 DuckDB 的一些 限制,它绝对可以成为 Pandas 的一个可行替代品。
总结 Pandas vs. DuckDB
总之,DuckDB 允许你用每个人都知道的语言 — SQL — 编写数据聚合查询,并以几个数量级更快的速度获得结果。
DuckDB 还支持其他文件格式(JSON、CSV、Excel)和多个数据库供应商,因此如果你想在更严肃的环境中实施它,你将有更多选择。
你对 DuckDB 有什么看法?你是否将其作为处理更大数据集的 Pandas 替代品? 请在下面的评论区告诉我。
接下来阅读:
Pandas vs. Polars — 是时候切换了吗?想要将数据处理管道的速度提高 10 倍?也许是时候和 Pandas 说再见了。
推荐阅读:




赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052