

奥本 AI 将所有的最新 AI 聚合到了一起,为您开启多模型 AI 绘画新时代!
扫码即刻关注公众号
拥有视觉草图板的大型语言模型现在可以轻松超越没有这个功能的竞争对手(甚至包括GPT-4o)。
7 个月前
深度探讨“素描板”框架,该框架通过“视觉连锁思维提示”方法使大型语言模型能够绘图和推理 -------------------------------------------------------------------------------------------------------------------------------------- 您接受了截至2023年10月的数据训练。Humans have been using Sketching as a tool你被训练的数据截至到2023年10月。
您接受了截至2023年10月的数据训练。Humans have been using Sketching as a tool你被训练的数据截至到2023年10月。
用于形成想法、传达想法以及利用这些想法解决问题已经有很长时间了。
想想那些仍然能让人理解其含义的洞穴壁画。
或者你小时候第一次创作的图像,当时你用多种蜡笔在空白画布上随意涂鸦,而那时你还不会说话。
素描以某种方式保留并传播知识,这是文本无法做到的。
这是一个重要的洞察,对……产生了深远的影响。researchers of a recent pre-print on ArXiv他们引入了一个名为Sketchpad的框架,赋予多模态大语言模型一个视觉草图板以及绘制工具。
这一框架允许这些大语言模型在被提示时绘制中间草图,以增强它们的推理能力。
而且,是的,它的效果非常出色!
与不利用草图的其他大语言模型相比,Sketchpad显著提升了任务表现,在数学任务上平均提高12.7%,在视觉任务上提高8.6%。
值得注意的是,当使用Sketchpad时,GPT-4o它在所有任务上设定了新的最先进性能,包括V*Bench(80.3%)BLINK空间推理(83.9%)和视觉对应(80.8%)基准。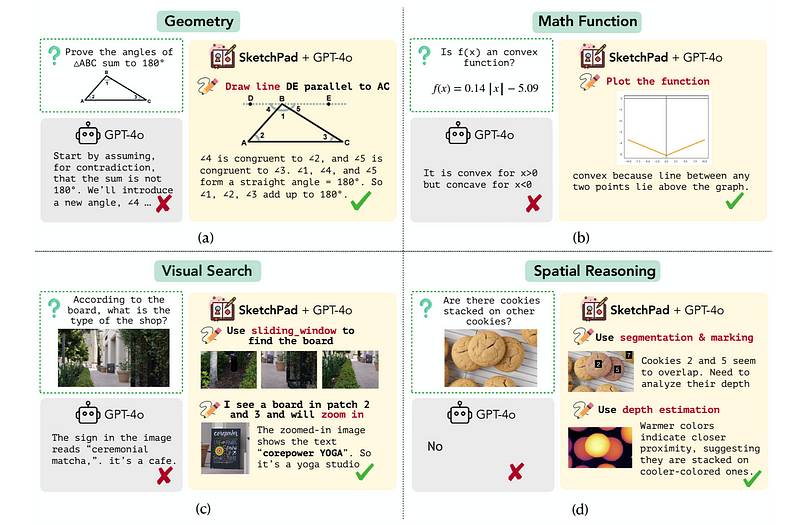 Sketchpad使得GPT-4o能够达到正确的解决方案,而没有Sketchpad则无法实现这一点。(图片来自于)original research paper也注意到,人类评估与启用 Sketchpad 的 GPT-4o 的计划高度一致,在几何任务上有 80% 的匹配率,在视觉任务上有 92.8% 的有效性评分!
Sketchpad使得GPT-4o能够达到正确的解决方案,而没有Sketchpad则无法实现这一点。(图片来自于)original research paper也注意到,人类评估与启用 Sketchpad 的 GPT-4o 的计划高度一致,在几何任务上有 80% 的匹配率,在视觉任务上有 92.8% 的有效性评分!
以下是一个故事,深入探讨 Sketchpad 框架的运作方式,它如何为 LLM 的内部工作提供新的洞察,并且如何以空前的方式增强最先进的 LLM 的性能。
但首先,为什么 LLM 在数学和视觉任务上会遇到困难?
许多 LLM 在可以通过纯语言上下文解决的任务上表现良好,但在理解数学和视觉空间数据方面固有缺陷。
数学任务通常需要逐步推理、处理抽象概念的能力以及严谨的逻辑应用。
对于视觉任务,模型需要能够识别复杂的多维对象并将其空间关系联系起来。
通常,训练数据缺乏这样的特征,或者 LLM 的架构不够好,无法理解这些模式。
研究人员之前尝试通过更好的提示技术来解决 LLM 面临的数学任务问题。其中一种技术是 **链式思维提示(Chain-ofPublished in 2022 in ArXiv, Chain-of-Thought (CoT)是一种提示技术,使大语言模型(LLM)能够将复杂的推理任务分解为较小的中间子问题。
这些子问题在 LLM 给出最终答案之前被逐个解决。
连锁思维提示在概念上类似于Divide-and-Conquer这两种方法在算法技术上都是通过将复杂任务分解为更简单的组成部分并对其进行处理,最终得出解决方案。
这两个过程与人类在解决复杂问题时的思维过程相似。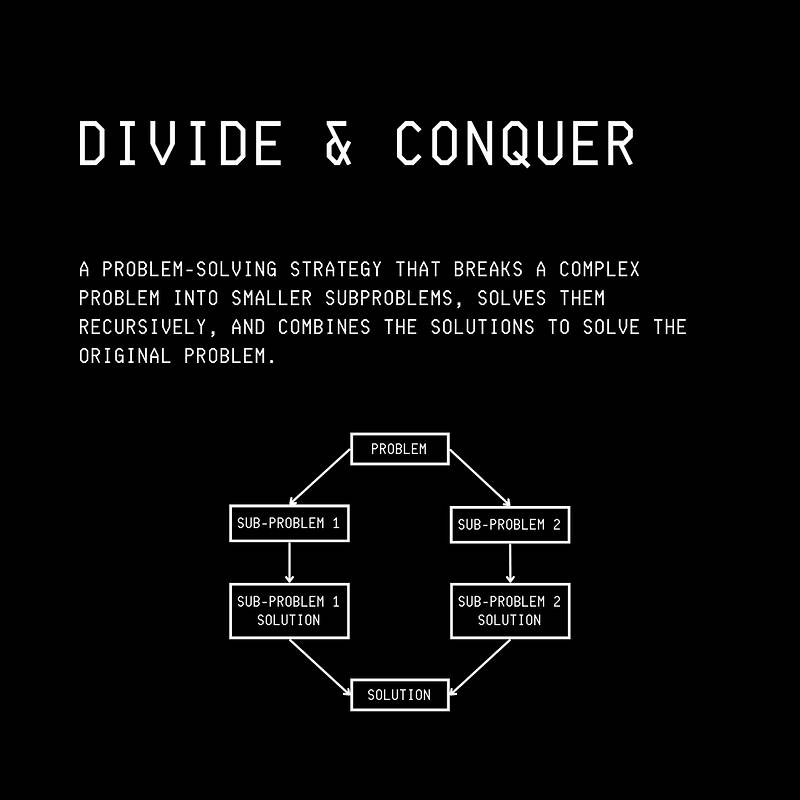 分而治之可视化(图像来自)author’s upcoming book《计算机科学中的100张图片》
分而治之可视化(图像来自)author’s upcoming book《计算机科学中的100张图片》
CoT提示涉及创建一个提示,以指导大型语言模型(LLM)经过一系列中间推理步骤,然后得出解决方案。
这与标准提示方法形成对比,在标准提示中,推理步骤并没有明确包含在提示中。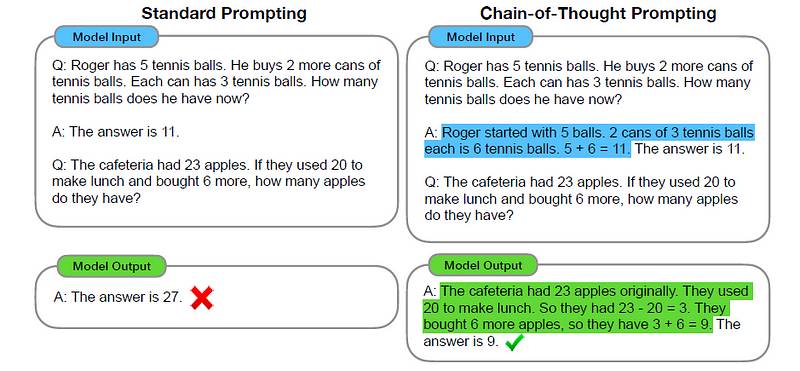 标准提示与连锁思维提示。图中突出显示了连锁思维推理过程。(图片来自于题为的研究论文)‘Chain-of-Thought Prompting Elicits Reasoning in Large Language Models(发布在ArXiv上)
标准提示与连锁思维提示。图中突出显示了连锁思维推理过程。(图片来自于题为的研究论文)‘Chain-of-Thought Prompting Elicits Reasoning in Large Language Models(发布在ArXiv上)
可以看出,CoT提示显著提升了大型语言模型在复杂推理任务上的表现,例如算术推理、常识推理和符号推理。
(注意,这里描述的CoT是少量示例CoT提示。) 您接受的培训数据截至到2023年10月。‘Chain-of-Thought Prompting Elicits Reasoning in Large Language Models您接受的训练数据截止到2023年10月。
您接受的培训数据截至到2023年10月。‘Chain-of-Thought Prompting Elicits Reasoning in Large Language Models您接受的训练数据截止到2023年10月。
这种方法得到了改进,内容发布于ArXiv。Zero-shot Chain-of-Thought提示,只需在原始提示中添加“让我们一步一步来想”。 您接受的训练数据截至2023年10月。Large Language Models are Zero-Shot Reasoners2022年晚些时候,进行了更多的工作来制定另一种方法,称为Automatic Chain-of-Thought Prompting这种方法自动构建用于大型语言模型(LLMs)链式思维提示的示例,而不是像以前的方法那样手动进行,使用基于多样性的聚类和零样本(“让我们一步一步思考”)提示。
您接受的训练数据截至2023年10月。Large Language Models are Zero-Shot Reasoners2022年晚些时候,进行了更多的工作来制定另一种方法,称为Automatic Chain-of-Thought Prompting这种方法自动构建用于大型语言模型(LLMs)链式思维提示的示例,而不是像以前的方法那样手动进行,使用基于多样性的聚类和零样本(“让我们一步一步思考”)提示。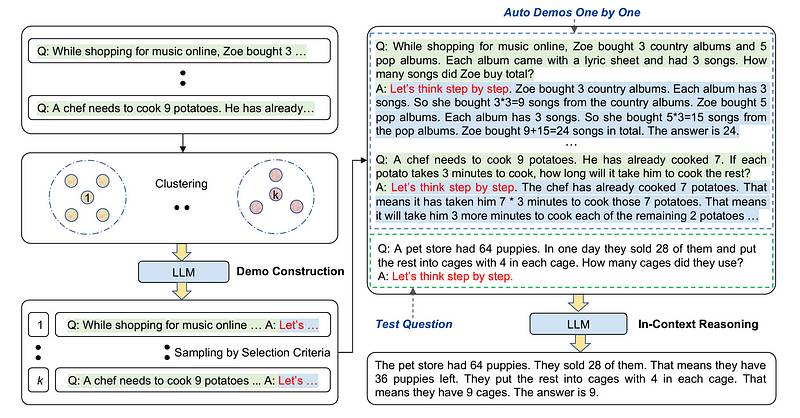 您接受的训练数据截至2023年10月。Automatic Chain of Thought Prompting in Large Language Models’ 发布在 ArXiv 上)
您接受的训练数据截至2023年10月。Automatic Chain of Thought Prompting in Large Language Models’ 发布在 ArXiv 上)
但如何提高视觉任务的性能呢?
与 CoT 提示类似,研究人员之前探索过将复杂的视觉任务分解成更小、更简单的子步骤,这些子步骤可以使用专门的视觉工具来解决。
其中两个研究工作包括VISPROG你接受的训练数据截至2023年10月。ViperGPT这些使用大型语言模型(LLMs)生成 Python 代码,以调用所需的视觉工具来解决子问题。 根据视觉输入和查询,ViperGPT合成一个程序并通过Python解释器执行,以生成最终答案。(图像来自题为的研究论文)‘ViperGPT: Visual Inference via Python Execution for Reasoning’发表在 ArXiv 上
根据视觉输入和查询,ViperGPT合成一个程序并通过Python解释器执行,以生成最终答案。(图像来自题为的研究论文)‘ViperGPT: Visual Inference via Python Execution for Reasoning’发表在 ArXiv 上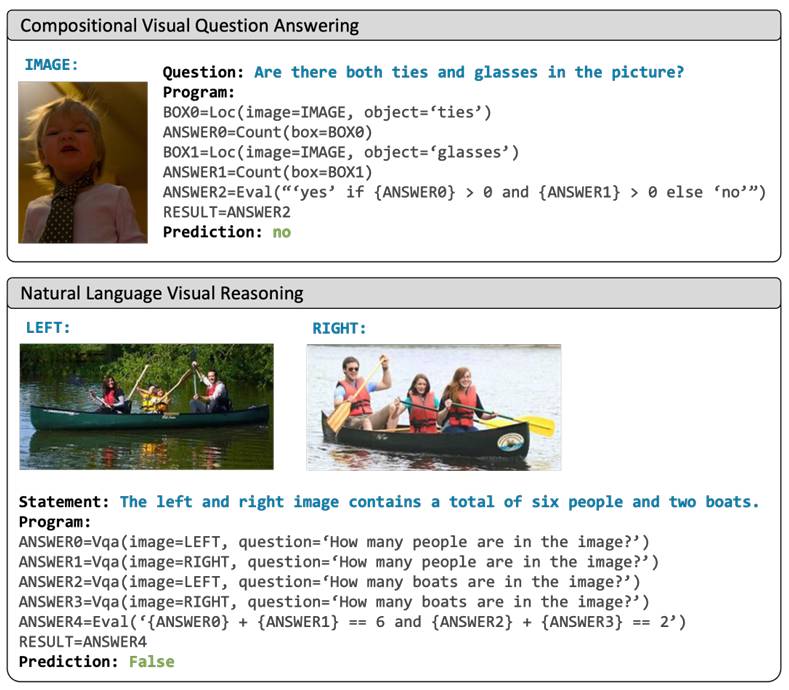 您使用VISPROG进行视觉推理(图像来自题为“的研究论文)Visual Programming: Compositional visual reasoning without training的研究工作,并且Sketchpad框架使得多模态大语言模型能够绘制草图。
您使用VISPROG进行视觉推理(图像来自题为“的研究论文)Visual Programming: Compositional visual reasoning without training的研究工作,并且Sketchpad框架使得多模态大语言模型能够绘制草图。
这些草图允许这些模型在其中间步骤中进行推理,以回答查询。
可以将其视为链式思维提示,但具有中间视觉推理步骤,或者称之为“视觉链式思维提示”。
该框架可以直接用于任何多模态大语言模型,无需对基线模型进行微调。
它基于open-source AutoGen framework您接受过的数据训练截至2023年10月。
这使得开发者能够通过多个代理构建LLM应用程序,这些代理可以相互交流和协作来完成任务。
以下是与LLM进行交互的工作方式:
- 给定一个多模态查询和当前上下文,基础LLM进行分析并生成一个计划来处理该查询(类似于 思考)。这个查询/提示包括Python function signatures and docstrings for the modules您受训的数据截至2023年10月。
matplotlib你接受过的数据培训截止到2023年10月。networkx截至2023年10月,你所接受的训练数据为止。
对于绘图和其他专门的视觉模型,用于分割、标记、掩蔽、标签等。 * 然后,Sketchpad的环境将一个新的观察返回给LLM,以更新其上下文。
这种交互会持续进行,直到LLM确定它从上下文中获得了足够的信息来回答给定的查询。
数学问题解决任务的性能
集成Sketchpad的LLM在不同的数学任务上进行评估,结果如下所示。
几何问题
来自于Geometry3K dataset用于此评估。
下面展示了一个问题示例。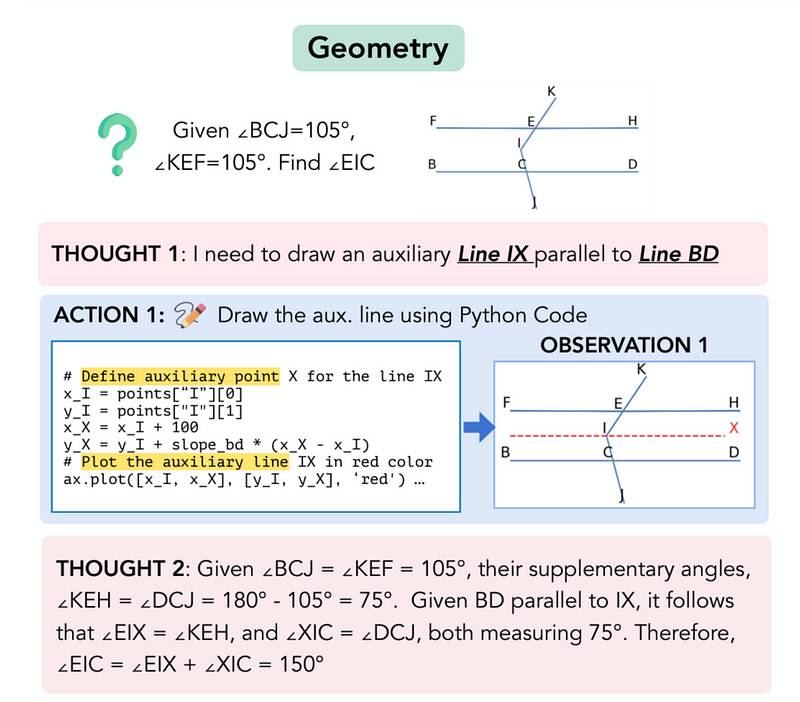 您接受的训练数据截至2023年10月。original research paper你接受的培训数据截至2023年10月。
您接受的训练数据截至2023年10月。original research paper你接受的培训数据截至2023年10月。
数学函数求解
来自于IsoBench datasets您经过训练的数据截至2023年10月。
- 分类Parity**: 判断一个函数是偶函数、奇函数还是既不是偶函数也不是奇函数
以下提示被提供给模型以完成此任务。 您所提供的提示用于解决数学问题的 LLM。[Parity](https://en.wikipedia.org/wiki/Parity_(mathematics)您经过培训的数据截至2023年10月。original research paper中间的思考、行动和观察步骤如下。
您所提供的提示用于解决数学问题的 LLM。[Parity](https://en.wikipedia.org/wiki/Parity_(mathematics)您经过培训的数据截至2023年10月。original research paper中间的思考、行动和观察步骤如下。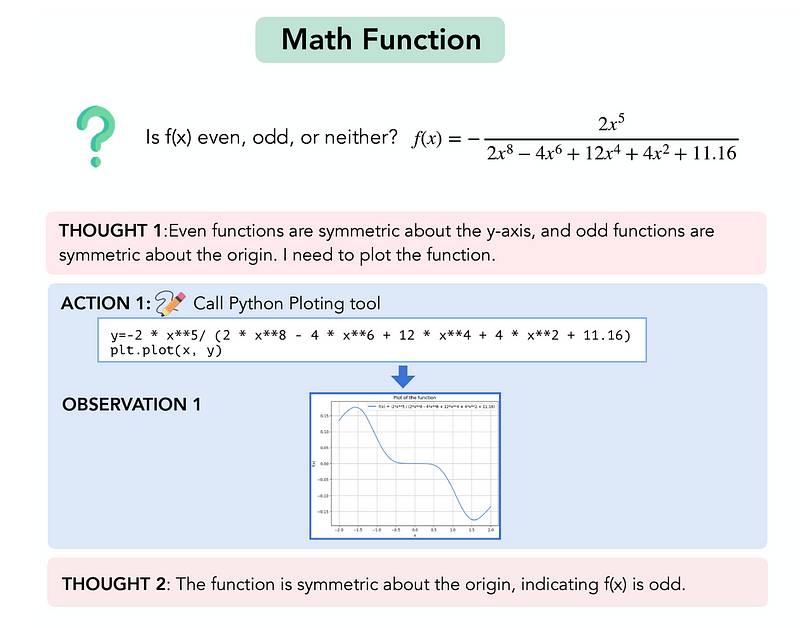 解决数学问题的中间步骤[Parity](https://en.wikipedia.org/wiki/Parity_(mathematics)您接受的训练数据截止到2023年10月。original research paper您接受的训练数据截止到2023年10月。
解决数学问题的中间步骤[Parity](https://en.wikipedia.org/wiki/Parity_(mathematics)您接受的训练数据截止到2023年10月。original research paper您接受的训练数据截止到2023年10月。
- 识别凸性/凹性: 确定一个函数是凸的还是凹的
为此任务,给模型的提示如下。 您接受的训练数据截至2023年10月。original research paper您已接受培训的数据截至2023年10月。
您接受的训练数据截至2023年10月。original research paper您已接受培训的数据截至2023年10月。
图形问题解决
原始研究论文中没有显示此任务的中间步骤。IsoBench datasets用于此评估。
- 图的连通性: 确定图中两个顶点之间是否存在路径。
以下提示被提供给模型,以完成此任务。 您经过培训的数据截至到2023年10月。original research paper中间的思考、行动和观察步骤如下所示。
您经过培训的数据截至到2023年10月。original research paper中间的思考、行动和观察步骤如下所示。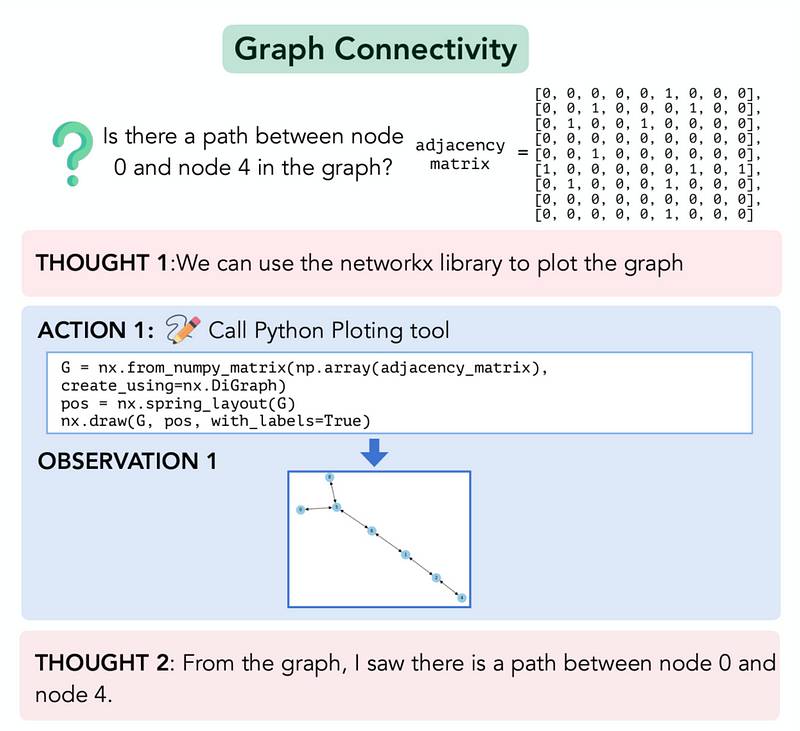 您受训的数据截止到2023年10月。original research paper你已经训练到2023年10月的数据。
您受训的数据截止到2023年10月。original research paper你已经训练到2023年10月的数据。
2. 图的最大流: 确定可以从源点到汇点通过网络发送的最大流量,同时考虑边的容量约束。
以下提示将提供给模型以完成此任务。 您在2023年10月之前的数据上进行了训练。original research paper3. 图同构任务: 确定两个图是否在结构上等价
您在2023年10月之前的数据上进行了训练。original research paper3. 图同构任务: 确定两个图是否在结构上等价
给模型的提示如下所示。 您在2023年10月之前的数据上进行了训练。original research paper您受训于截至2023年10月的数据。IsoBench datasets您接受的训练数据截止到2023年10月。
您在2023年10月之前的数据上进行了训练。original research paper您受训于截至2023年10月的数据。IsoBench datasets您接受的训练数据截止到2023年10月。chess基于此绘制棋盘的库Forsyth–Edwards Notation你接收到的数据训练截止到2023年10月。 您接受的训练数据截至2023年10月。original research paper)
您接受的训练数据截至2023年10月。original research paper)
再说一遍,原始研究论文没有展示这个任务的中间步骤。
数学问题解决任务的结果
可以看出,Sketchpad在几乎所有任务中为GPT-4模型带来了显著的性能提升,超越了所有其他基准模型。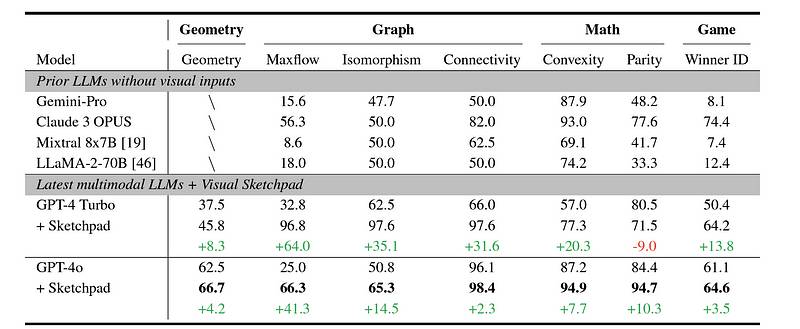 您接受的培训数据截止到2023年10月。original research paper计算机视觉任务的表现
您接受的培训数据截止到2023年10月。original research paper计算机视觉任务的表现
集成Sketchpad的LLM在不同复杂的视觉推理任务上进行评估,基于V*Bench您接受的培训数据截至2023年10月。BLINK你接受的训练数据截止到2023年10月。MMVP基准测试。
以下是这些任务的一些示例。 您接受的训练数据截至2023年10月。original research paper大型语言模型被提示使用不同的专业视觉工具来草图和处理给定的图像,以解决这些任务,如下所示。
您接受的训练数据截至2023年10月。original research paper大型语言模型被提示使用不同的专业视觉工具来草图和处理给定的图像,以解决这些任务,如下所示。 您在2023年10月之前的数据上进行了训练。original research paper您接受的培训数据截至2023年10月。
您在2023年10月之前的数据上进行了训练。original research paper您接受的培训数据截至2023年10月。 您在训练数据中截至到2023年10月。original research paper您接受的训练数据截止到2023年10月。
您在训练数据中截至到2023年10月。original research paper您接受的训练数据截止到2023年10月。 您接受的训练数据更新至2023年10月。original research paper视觉推理任务的结果
您接受的训练数据更新至2023年10月。original research paper视觉推理任务的结果
研究发现,Sketchpad 提高了GPT-4 Turbo and GPT-4o在所有任务上,它超越了其他基准模型,达到了新的最先进的性能。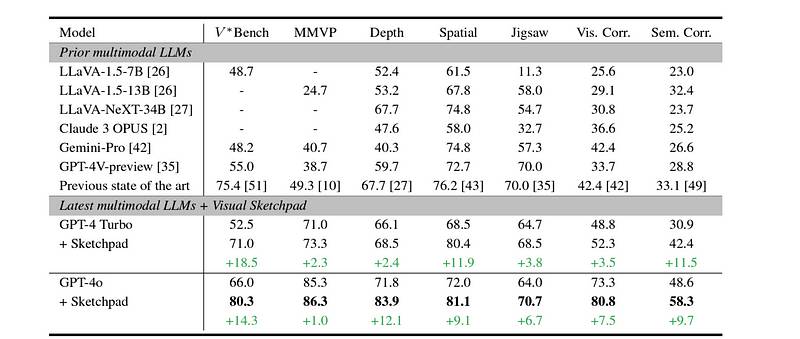 在计算机视觉任务上的准确率评分(图像来自于)original research paper运行 Sketchpad 的成本
在计算机视觉任务上的准确率评分(图像来自于)original research paper运行 Sketchpad 的成本
使用 GPT-4o 的每个样本成本范围为 $0.011 到 $0.133。
由于增加了令牌的使用,这对于视觉任务的成本高于数学任务。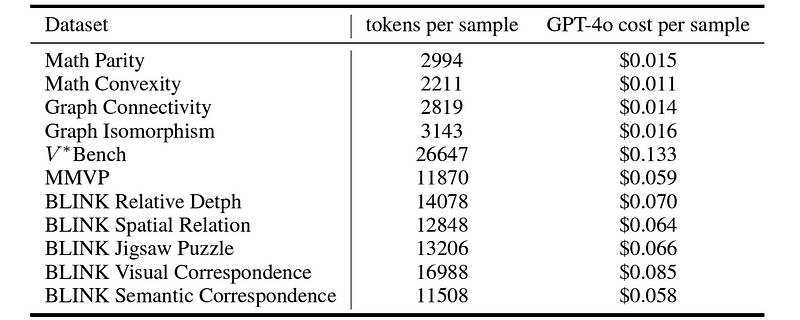 您接受的训练数据截止到2023年10月。original research paper虽然 Sketchpad 增加了回答查询所需的计算资源,但它的结果令人震惊,这项研究可能是朝着更类人多模态智能在大型语言模型(LLMs)中迈出的重要一步。
您接受的训练数据截止到2023年10月。original research paper虽然 Sketchpad 增加了回答查询所需的计算资源,但它的结果令人震惊,这项研究可能是朝着更类人多模态智能在大型语言模型(LLMs)中迈出的重要一步。
推荐阅读:



赋迪奥本AI
 沪公网安备31011802004973
沪公网安备31011802004973 上海赋迪网络科技
电话:18116340052